Author: Denis Avetisyan
New research reveals that a surprising number of errors in question answering stem not from a lack of knowledge, but from questions that are poorly defined and open to interpretation.
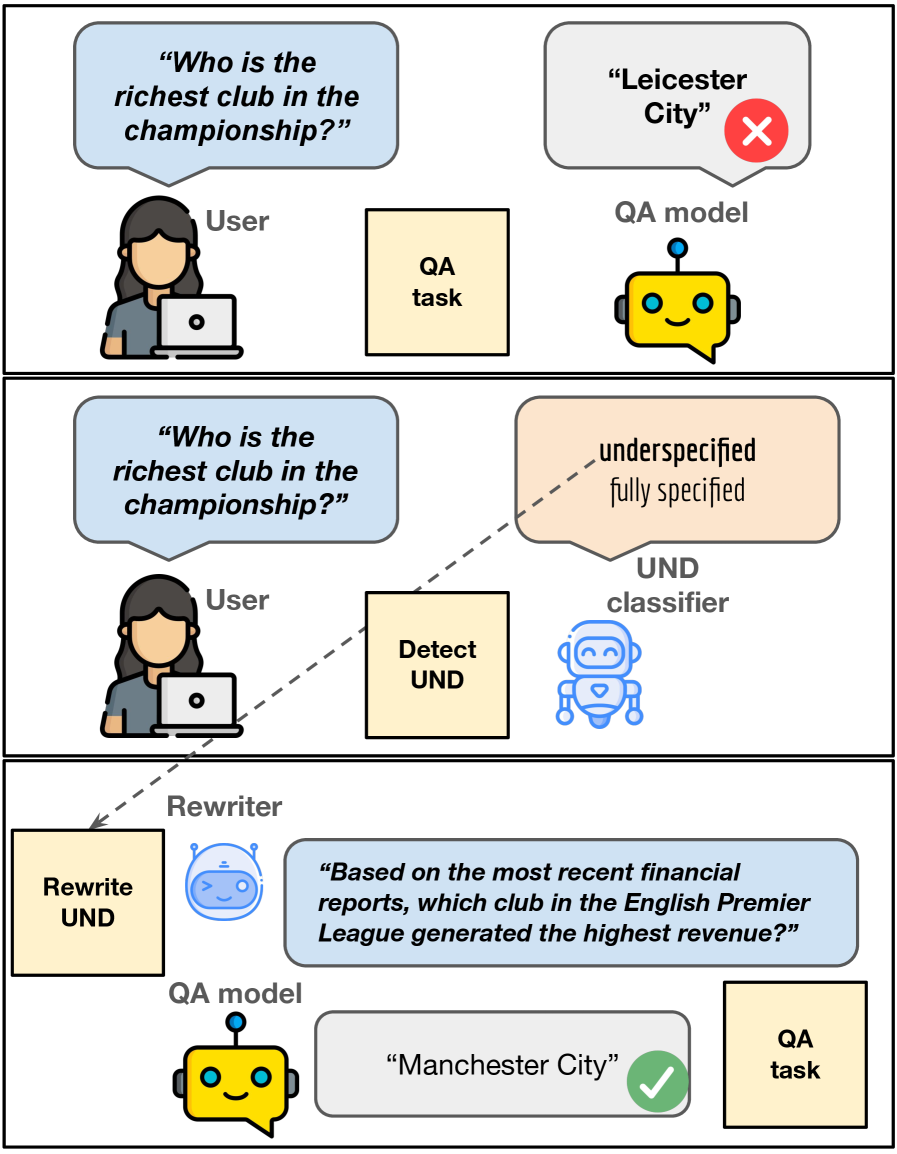
Detecting and rewriting underspecified questions significantly improves the performance of large language models on question answering benchmarks.
Despite advances in large language models, question answering benchmarks remain surprisingly challenging, raising questions about whether failures stem from model limitations or inherent ambiguities in the questions themselves. This work, ‘Who is the richest club in the championship? Detecting and Rewriting Underspecified Questions Improve QA Performance’, investigates the prevalence of underspecified questions – queries requiring external context for unique interpretation – and their impact on performance. The authors demonstrate that a substantial portion of benchmark questions are underspecified, and rewriting them for clarity consistently improves question answering results, suggesting many errors arise from question ambiguity rather than model deficiencies. Could addressing question clarity be a critical step toward more accurate and meaningful evaluation of large language models?
The Hidden Costs of Ambiguity in Questioning
Despite remarkable progress in artificial intelligence, current question answering (QA) systems consistently falter when confronted with questions lacking clear context or sufficient detail – a phenomenon known as underspecification. These questions, common in everyday human conversation, present a significant challenge because they require the system to infer missing information or disambiguate multiple possible interpretations. Unlike well-defined queries with explicit parameters, underspecified questions rely heavily on shared background knowledge and contextual understanding, capabilities that remain difficult for machines to replicate. This inherent weakness means that even sophisticated QA models can produce inaccurate, irrelevant, or nonsensical answers when faced with ambiguity, underscoring a critical limitation in their ability to truly understand and respond to natural language.
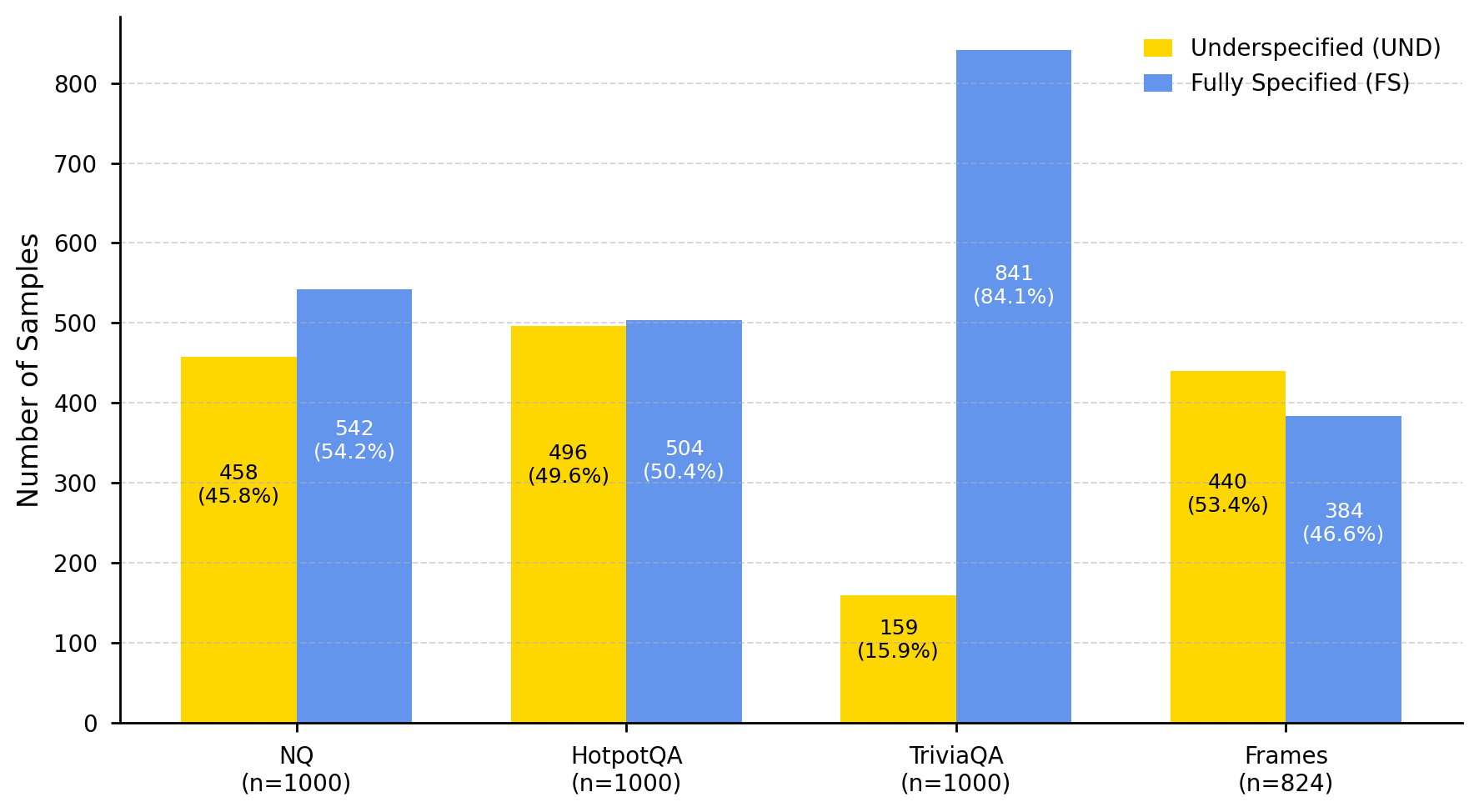
Question answering systems, despite recent progress, frequently encounter queries that lack the necessary detail for a definitive response – a phenomenon known as underspecification. Analyses reveal that a substantial portion of real-world questions, ranging from approximately 16% to over 53% across established datasets like TriviaQA and FRAMES, fall into this ambiguous category. This prevalence of underspecified questions directly contributes to inaccurate or irrelevant answers, exposing a significant vulnerability in current QA robustness. The inability to effectively handle such queries underscores a critical gap between the performance of these systems on curated benchmarks and their reliability in practical applications, ultimately limiting their trustworthiness and usefulness to end-users.
A comprehensive grasp of question underspecification is paramount to advancing question answering systems beyond current limitations. Identifying the specific types of contextual gaps-whether they involve coreference resolution, implicit assumptions, or ill-defined entities-allows for the development of targeted mitigation strategies. Such strategies might include prompting the user for clarification, leveraging common-sense knowledge to infer missing information, or employing probabilistic models to handle ambiguity. Ultimately, a deeper understanding of how humans naturally resolve underspecification in conversation can inform the creation of AI systems that not only provide accurate answers but also demonstrate a more nuanced and human-like interaction style, fostering greater trust and reliability in real-world applications.
The reliability of current question answering (QA) system evaluations is significantly undermined by the prevalence of underspecified questions. Standard benchmarks, designed to measure a system’s capabilities, often fail to account for ambiguities inherent in real-world queries; a QA system might appear successful on a dataset, but perform poorly when confronted with questions lacking sufficient context in practical applications. This discrepancy extends beyond academic evaluation, directly impacting the trustworthiness of deployed QA solutions used in customer service, information retrieval, and virtual assistants. If a system consistently misinterprets or fails to address underspecified questions, user confidence erodes, and the potential for misinformation or incorrect actions increases – highlighting the critical need to address this hidden weakness for truly robust and dependable QA technology.
Pinpointing the Sources of Uncertainty
An LLM-based classifier is critical for automated identification of underspecified questions, differentiating them from fully specified questions within question answering (QA) datasets. This classification is achieved by training a large language model to predict whether a given question contains sufficient information for a definitive answer without requiring external context or inference. The classifier’s output-a binary label indicating ‘fully specified’ or ‘underspecified’-enables targeted analysis of model performance; specifically, it allows researchers to isolate and quantify errors stemming from ambiguity. Furthermore, this capability facilitates focused dataset improvement by flagging instances requiring clarification or augmentation with relevant contextual data, ultimately leading to more robust and reliable QA systems.
A taxonomy of underspecification categorizes ambiguity types in questions to facilitate detailed analysis. This framework identifies distinctions such as missing referents, where a question relies on unstated entities; scope ambiguity, involving unclear ranges of application; vague predicates, utilizing terms with imprecise definitions; and implicit assumptions, requiring background knowledge not explicitly provided. By classifying ambiguity in this manner, researchers can move beyond simply identifying ambiguous questions to understanding why they are ambiguous, enabling targeted development of mitigation techniques and more precise evaluation of question answering systems. This granular categorization supports a nuanced understanding of the challenges posed by underspecification and informs strategies for improving question clarity and system robustness.
Underspecification analysis involves systematically evaluating question-answer datasets to determine the frequency with which questions lack the necessary information for a definitive answer. This process moves beyond simple accuracy metrics by explicitly identifying instances of ambiguity. Datasets are annotated to categorize questions as either fully specified or underspecified, allowing for quantitative measurement of the problem’s scope. Results consistently demonstrate a significant correlation between underspecification and reduced model performance; a higher proportion of underspecified questions within a dataset typically leads to lower overall accuracy scores, highlighting the practical impact of ambiguity on question answering systems.
Effective mitigation of underspecification in question answering (QA) requires identifying its primary causes: missing contextual information, the use of vague or ambiguous terminology, and reliance on unstated assumptions. Analysis consistently demonstrates a statistically significant reduction in accuracy when models process underspecified (UND) questions compared to fully specified (FS) questions; t-tests across multiple datasets and model architectures confirm this performance gap. This discrepancy highlights that current QA systems struggle with questions lacking sufficient explicit information, necessitating targeted strategies to address these deficiencies and improve robustness.
Refining Questions for Clarity and Precision
LLM-based question rewriting addresses the common issue of underspecified queries by automatically enriching them with necessary context and resolving inherent ambiguities. This process leverages the generative capabilities of large language models to transform vague questions into fully specified ones, effectively providing the model with a clearer understanding of the information being requested. By explicitly defining implicit assumptions and adding relevant details, the rewritten questions enable more accurate and reliable answers from question answering systems, as the LLM can directly address the intended meaning of the query rather than attempting to infer it.
Large language models, specifically GPT-4o and Gemini-2.5-Flash, facilitate question rewriting through their inherent generative capabilities. These models are not simply retrieving information; they are constructing new, fully-specified questions based on the initial, underspecified input. This process leverages the models’ ability to understand semantic meaning, infer missing information, and generate coherent text. The models’ parameters, trained on massive datasets, enable them to probabilistically predict the most likely and contextually relevant additions to the original query, effectively transforming ambiguous questions into those that are readily answerable by question answering systems. The models’ performance in this capacity is directly related to their scale and the quality of their training data.
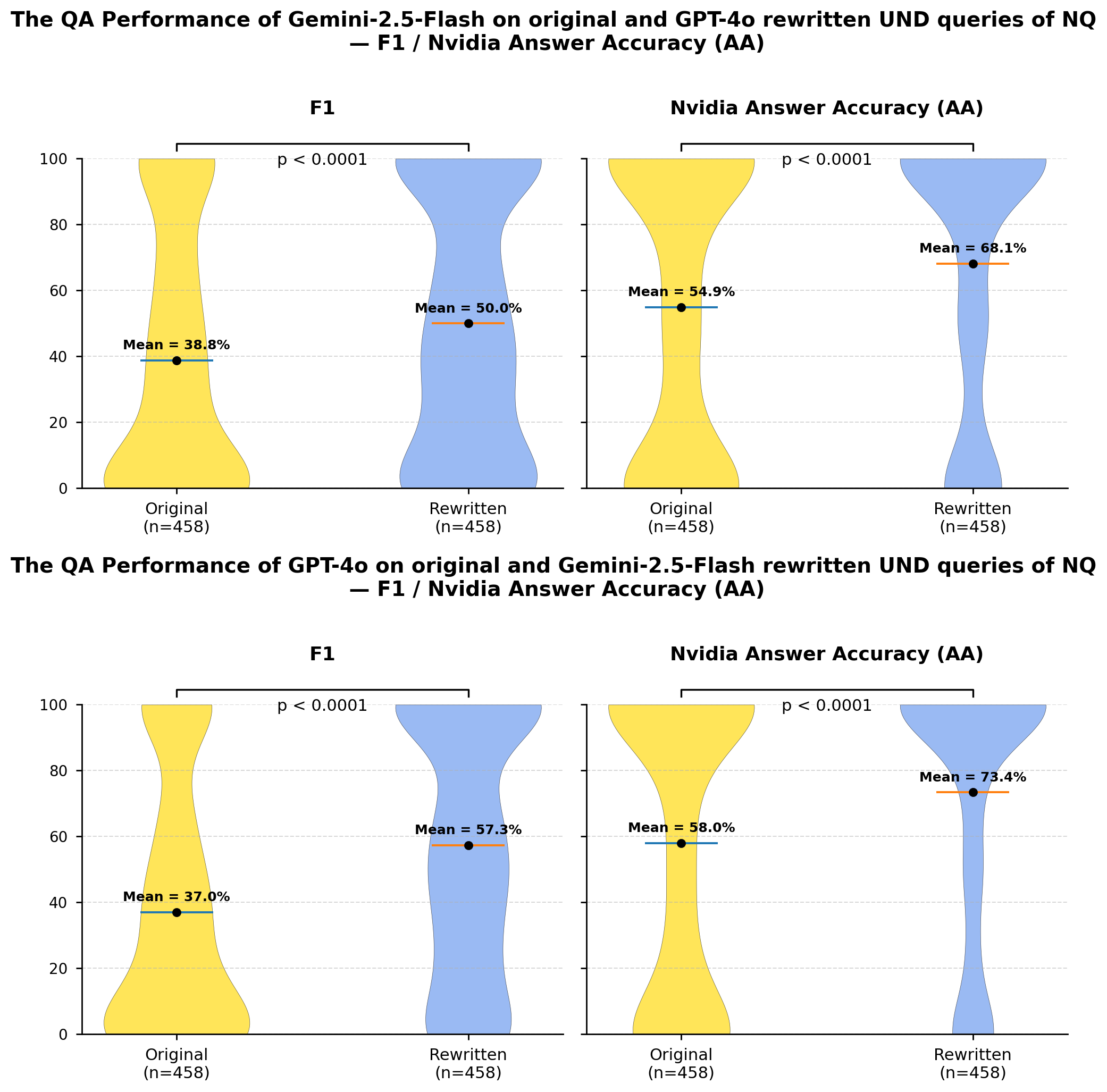
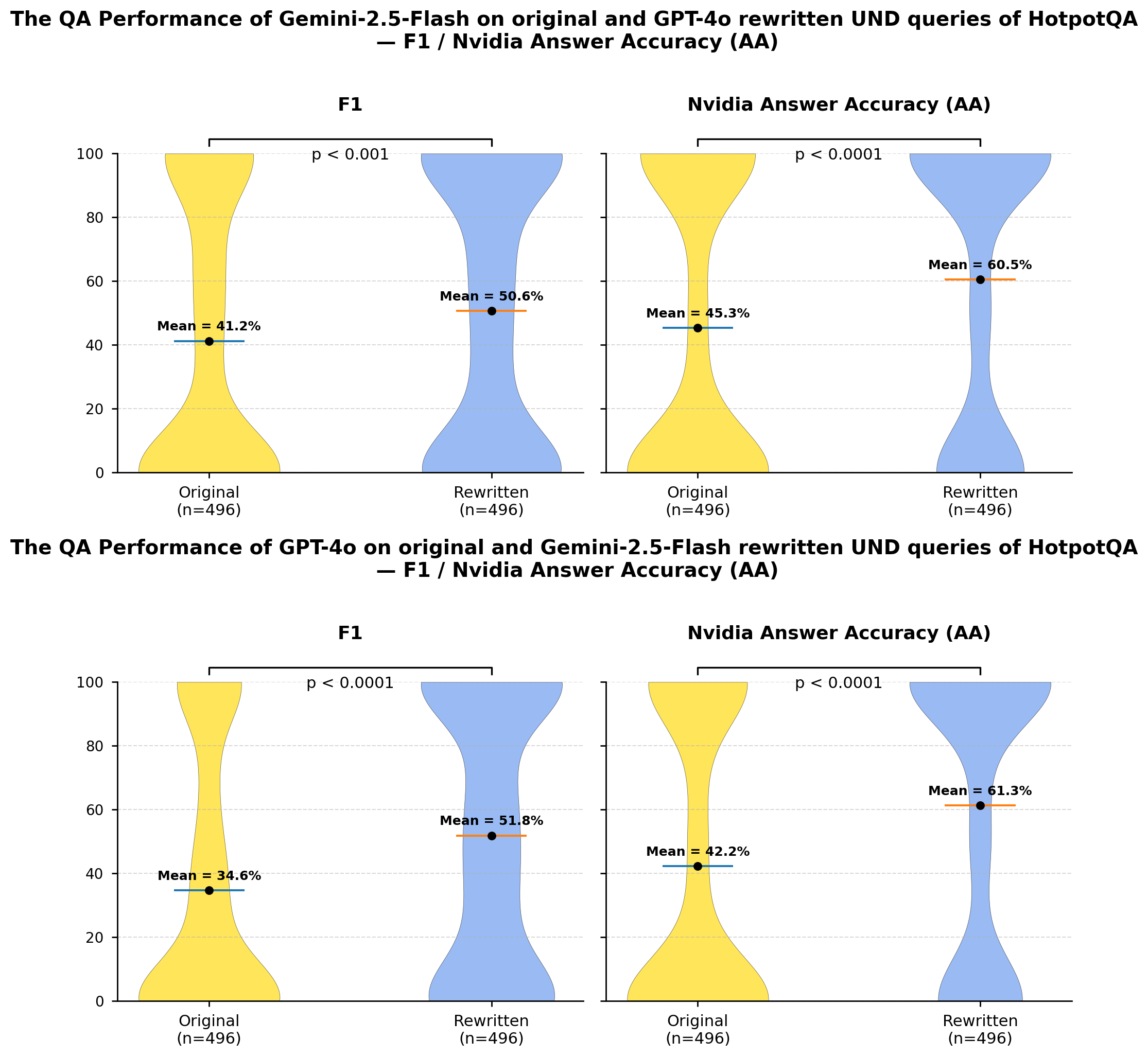
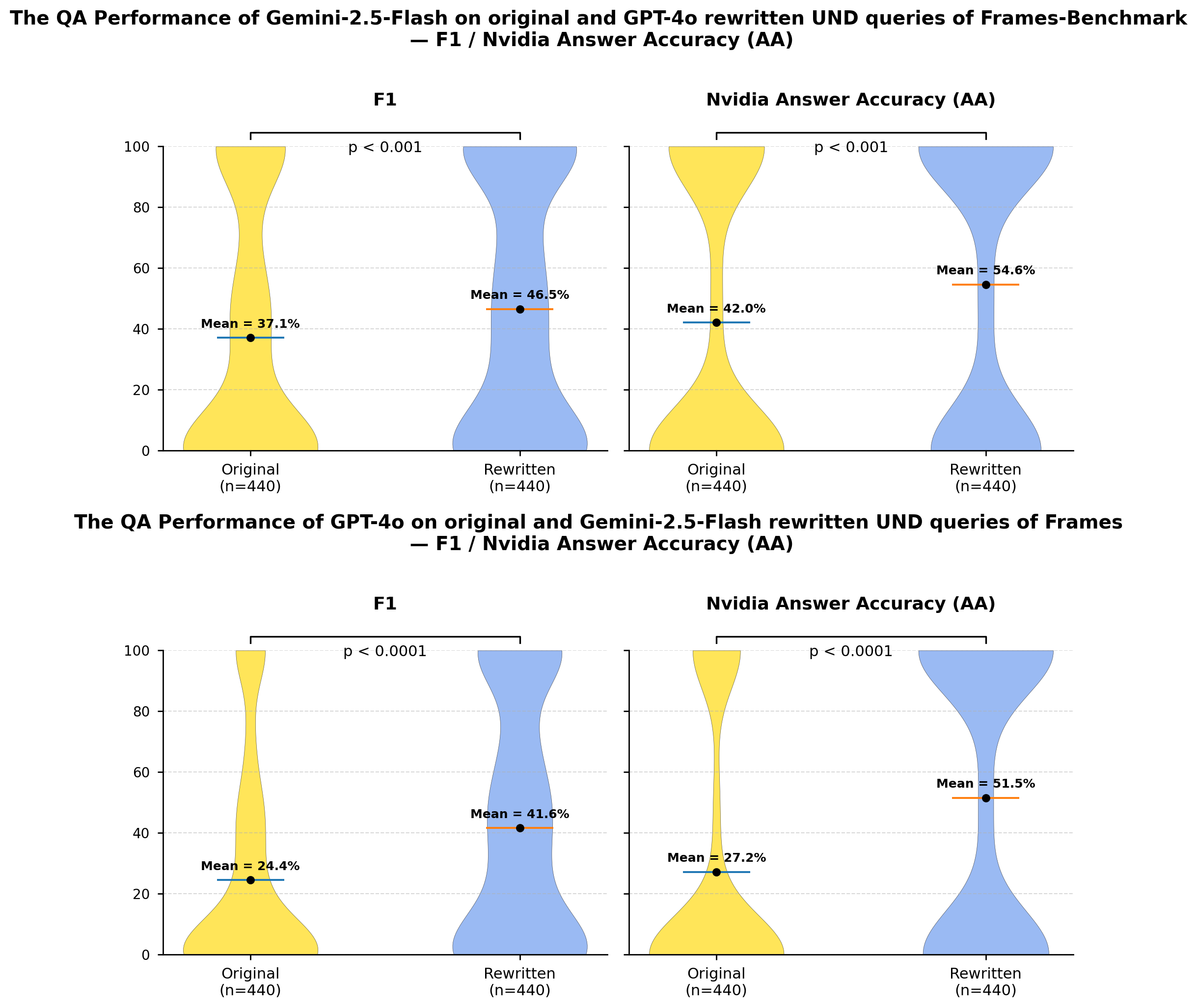
A controlled experiment was conducted to quantify the effectiveness of question rewriting strategies on question answering (QA) performance. This experiment involved assessing the percentage of underspecified (UND) questions successfully transformed into fully specified questions through automated rewriting. Results indicate a rewriting success rate ranging from 64% to 86%, demonstrating that this percentage of initially ambiguous queries can be clarified sufficiently to enable accurate QA processing. This measured success rate provides a baseline for comparing different rewriting approaches and optimizing their integration within QA systems.
Automated clarification of ambiguous questions directly addresses a primary source of error in question answering (QA) systems. Underspecified or poorly defined queries often lead to irrelevant or inaccurate responses, impacting system reliability and introducing inconsistency. By proactively resolving ambiguity through question rewriting – adding necessary context and detail – the system minimizes misinterpretations and focuses on the user’s intended information need. This process increases the probability of retrieving correct answers and ensures more consistent performance across a wider range of input queries, ultimately improving the overall trustworthiness of the QA system.
Validating Improvements Through Rigorous Assessment
Determining the effectiveness of question rewriting hinges on robust performance evaluations using standardized datasets. Collections like the FRAMES Dataset provide a critical benchmark for assessing how these techniques impact the accuracy and reliability of question answering systems. By subjecting rewritten questions – and their corresponding answers – to rigorous testing against established ground truths, researchers can quantitatively measure improvements. This process isn’t simply about achieving a higher score; it’s about understanding how rewriting clarifies ambiguity and enables systems to extract more precise information. Without this systematic evaluation, improvements remain anecdotal, and the true benefits of question refinement cannot be reliably demonstrated or applied to real-world applications.
Evaluating the quality of answers generated by Retrieval-Augmented Generation (RAG) systems requires more than simple accuracy checks; a holistic framework is crucial. The RAGAS (Retrieval-Augmented Generation Assessment) framework addresses this need by providing a suite of metrics designed to dissect answer quality from multiple angles. Key among these is Nvidia Answer Accuracy, which assesses whether the generated response is factually consistent with the provided context. However, RAGAS extends beyond this, also measuring context relevance – ensuring the retrieved information actually supports the answer – and faithfulness, verifying that the answer doesn’t introduce information absent from the source. By combining these metrics, RAGAS offers a comprehensive and nuanced evaluation, allowing developers to pinpoint specific areas for improvement in their RAG pipelines and build more reliable, trustworthy question answering systems.
A direct comparison of question answering performance before and after question rewriting reveals the substantial advantages of mitigating underspecification. Recent evaluations, leveraging the HotpotQA dataset and the GPT-4o model, demonstrate a performance increase of up to 22.1% when utilizing rewritten questions. This improvement signifies that addressing ambiguity and clarifying intent within the initial query substantially enhances the accuracy of the generated answers. The observed gains are not merely statistical; they represent a tangible enhancement in the system’s ability to correctly interpret user needs and deliver relevant, precise responses, validating the effectiveness of this approach to question refinement.
Rigorous evaluation confirms the efficacy of this question rewriting approach, demonstrating its capacity to significantly enhance the performance of real-world question answering systems. The observed improvements, substantiated by gains of up to 22.1% on the HotpotQA dataset, aren’t merely statistical anomalies; they represent a tangible increase in the reliability and accuracy of information retrieval. This translates directly to benefits across a broad spectrum of applications, from virtual assistants and customer service chatbots to complex data analysis tools and knowledge discovery platforms. By effectively addressing issues of underspecification, the technique allows systems to better interpret user intent and deliver more relevant, precise responses, ultimately fostering greater user trust and satisfaction.
The pursuit of quantifiable metrics, as demonstrated by this study on question answering, often obscures fundamental ambiguities. The research highlights how ‘underspecification’ within questions introduces noise, demanding careful consideration of input clarity. This echoes John von Neumann’s assertion: “The best way to predict the future is to invent it.” The ability to invent precise questions, rather than accept poorly defined ones, is crucial for reliable evaluation. By actively rewriting queries to eliminate ambiguity, the study doesn’t merely measure LLM performance-it actively shapes the conditions under which that performance is assessed, mirroring von Neumann’s emphasis on proactive creation rather than passive observation. The paper’s focus on data annotation as a means of achieving this precision is a testament to the power of deliberate design.
What Remains to be Seen
The present work identifies a familiar failing: the presumption of shared understanding. Question answering systems, and those who construct their benchmarks, operate on the tacit belief that a question’s incompleteness is not a flaw, but an assumed context. This is, plainly, an act of self-deception. The observed performance gains from explicit specification are not merely incremental; they reveal the extent to which current evaluation metrics measure a system’s ability to guess intent, rather than demonstrate genuine comprehension. The field must now confront the uncomfortable truth that many reported successes are, in essence, triumphs of statistical inference over semantic understanding.
Future work should not focus on increasingly complex models, but on increasingly rigorous annotation practices. The cost of precision is high, but the cost of imprecision-of mistaking correlation for cognition-is far greater. A useful next step involves extending this analysis beyond simple factual queries to encompass questions demanding reasoning, inference, or nuanced interpretation. Such questions will undoubtedly expose even greater levels of implicit assumption.
Ultimately, the goal is not to build systems that answer underspecified questions, but to build systems that recognize their own limitations. A truly intelligent system should, at times, simply state what remains unknown, or request clarification. Such humility is, regrettably, rare in the current landscape.
Original article: https://arxiv.org/pdf/2602.11938.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- All Shadow Armor Locations in Crimson Desert
- Jujutsu Kaisen Season 3 Episode 12 Release Date
- Dark Marksman Armor Locations in Crimson Desert
- How to Get the Sunset Reed Armor Set and Hollow Visage Sword in Crimson Desert
- Top 5 Militaristic Civs in Civilization 7
- Keeping AI Agents on Track: A New Approach to Reliable Action
- How to Beat Antumbra’s Sword (Sanctum of Absolution) in Crimson Desert
- Sega Reveals Official Sonic Timeline: From Prehistoric to Modern Era
- Sakuga: The Hidden Art Driving Anime’s Stunning Visual Revolution!
- How To Beat Ator Archon of Antumbra In Crimson Desert
2026-02-15 03:03