Author: Denis Avetisyan
New research reveals that code created by artificial intelligence systems consistently repeats the same security flaws, creating opportunities for proactive attack prediction.
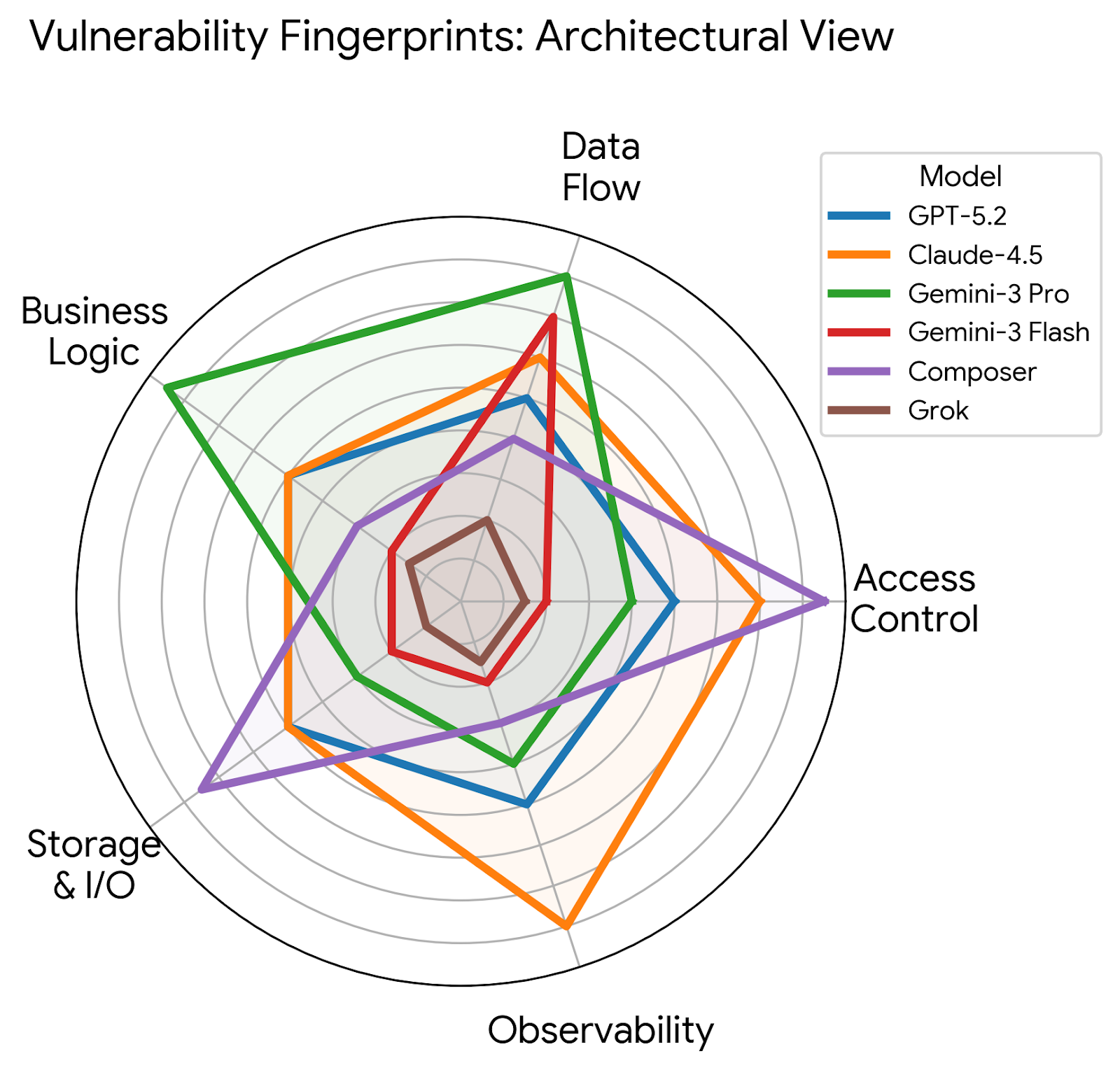
This study demonstrates recurring vulnerability patterns in black-box large language model-generated software and proposes a feature-security table for predicting exploitable code based on observable characteristics.
Despite the increasing reliance on large language models (LLMs) for code generation, a critical gap remains in understanding the systematic recurrence of vulnerabilities within their outputs. This paper, ‘Extracting Recurring Vulnerabilities from Black-Box LLM-Generated Software’, introduces the Feature–Security Table (FSTab) to reveal predictable patterns of weakness, enabling black-box attack prediction based on observable frontend features without access to source code. Our findings demonstrate strong cross-domain transfer of these vulnerabilities-achieving up to 94% attack success-suggesting a consistent, model-centric risk profile. Does this inherent reproducibility expose a fundamental and previously unquantified attack surface in LLM-generated software, demanding a shift towards proactive, model-aware security evaluations?
The Inherent Fragility of Automated Code
Large language models demonstrate a remarkable capacity for code generation, yet this very power inadvertently introduces consistent backend vulnerabilities. The issue isn’t simply that LLMs sometimes produce flawed code, but that specific patterns of insecure coding practices repeatedly emerge in the generated output. Researchers have identified predictable weaknesses – such as insufficient input validation, improper resource handling, and predictable random number generation – that consistently manifest across diverse coding prompts and tasks. This isn’t random error; the models, trained on vast datasets containing both secure and insecure code, appear to statistically favor certain solutions, sometimes replicating vulnerable patterns at scale. Consequently, even seemingly unique code generated by an LLM can harbor the same underlying weaknesses, creating a systemic risk for applications relying on this automated code synthesis.
Analysis reveals that security flaws arising from Large Language Model (LLM) code generation aren’t isolated incidents, but rather demonstrate a striking pattern of recurrence. Researchers have identified that LLMs, when tasked with code synthesis, consistently reproduce similar vulnerabilities across different prompts and applications – suggesting underlying systematic weaknesses in their approach. This isn’t simply a matter of chance; the models appear to favor certain coding structures or implementations that are inherently susceptible to exploits, like injection flaws or insecure deserialization. The observed repetition indicates that LLMs aren’t truly understanding security principles, but instead are statistically generating code based on patterns learned from their training data – patterns that unfortunately include many examples of vulnerable code. Consequently, a reliance on traditional, reactive security testing proves insufficient; a proactive strategy focused on understanding and mitigating these recurring weaknesses within the LLM’s code generation process is crucial for building secure applications.
Conventional security evaluations, designed to identify known attack vectors and explicit flaws, frequently fail to detect the nuanced vulnerabilities arising from Large Language Model (LLM) generated code. These LLMs, while proficient in syntax, often replicate patterns that introduce systemic weaknesses-subtle coding practices that, individually, may seem benign, but collectively create exploitable conditions. This necessitates a paradigm shift in evaluation methodologies, moving beyond simple bug hunting to focus on behavioral analysis and the identification of recurring, statistically significant flaws in the generated code’s logic and structure. A robust evaluation requires automated tools capable of recognizing these patterns at scale and assessing the aggregate risk they pose, rather than relying solely on manual code review or traditional penetration testing which are ill-equipped to handle the volume and unique characteristics of LLM-produced software.
Mapping Features to Vulnerabilities: A Black-Box Approach
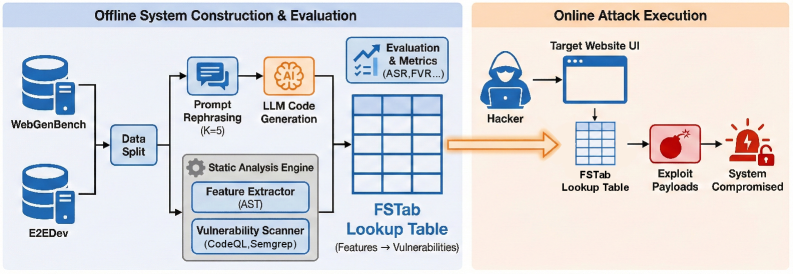
FSTab operates as a black-box attack and evaluation framework by establishing a direct correlation between frontend features – those elements of a software application directly observable by a user or through network requests – and potential vulnerabilities within the backend systems. This approach avoids the necessity of internal code analysis or access to the application’s underlying model; instead, it analyzes the application’s interface to identify input vectors and their potential to trigger exploitable conditions. By focusing on observable behaviors, FSTab facilitates vulnerability discovery without requiring knowledge of the internal implementation, increasing its applicability across diverse software architectures and LLM deployments.
Feature Extraction within FSTab operates by systematically identifying observable characteristics of the application’s frontend, such as form fields, buttons, and data displays. This process doesn’t require prior knowledge of the application’s internal workings; instead, it analyzes the user interface to define potential input vectors. These identified features are then automatically cataloged, creating a comprehensive list of data entry points and their associated parameters. This catalog serves as the basis for security testing, enabling the framework to generate and submit various inputs to assess the application’s vulnerability to attacks like injection or cross-site scripting, all without requiring access to the backend code or model.
Automated feature extraction within FSTab significantly improves the scalability of vulnerability assessments for complex applications. Traditional security testing often requires manual identification of input vectors and application features, a process that is both time-consuming and prone to oversight. FSTab’s automated approach systematically identifies these features by observing the application’s interface, creating a comprehensive catalog of potential attack surfaces. This automation allows for the analysis of a significantly larger number of features than would be feasible manually, and it facilitates repeated testing as the application evolves, providing continuous security validation without requiring substantial human effort or deep internal knowledge of the application’s codebase.
FSTab operates as a black-box testing framework, meaning it assesses Large Language Model (LLM) security without requiring access to the model’s internal parameters, weights, or training data. This is achieved by solely analyzing the LLM’s externally observable interface – the input and output behaviors. Consequently, FSTab is not tied to any specific LLM architecture; it functions identically regardless of whether the underlying model is based on transformers, recurrent neural networks, or other designs. This adaptability simplifies the evaluation process across diverse LLM deployments and facilitates consistent security testing even as models evolve or are replaced, eliminating the need for framework modifications with each new LLM version.
Quantifying the Persistence and Transfer of Vulnerabilities
Rephrasing Vulnerability Persistence (RVP) and Domain Vulnerability Recurrence (DVR) are quantitative metrics developed to assess the resilience of code generated by Large Language Models (LLMs) to both input perturbations and changes in the target application domain. RVP specifically measures the retention of vulnerabilities when prompts are semantically reworded, providing insight into a model’s sensitivity to minor input variations. DVR, conversely, evaluates vulnerability recurrence across different software domains, effectively determining if a vulnerability is intrinsic to the model’s generation process or tied to a specific application context. These metrics are calculated through automated testing using FSTab and provide a standardized method for benchmarking LLM code robustness, independent of specific vulnerability types or attack vectors.
Rephrasing Vulnerability Persistence (RVP) quantifies the degree to which vulnerabilities in Large Language Model (LLM)-generated code remain present despite semantic alterations to the input prompt. Analysis reveals RVP values between 35.53% and 50.94% for models including Composer and GPT-5.2. This indicates that, even when prompts are reworded to express the same intent, a substantial portion of the original vulnerabilities are retained in the generated code. The observed RVP values suggest a limited capacity of these models to generalize secure coding practices based on prompt variations, and highlight a concerning persistence of vulnerabilities even with seemingly innocuous input changes.
Feature Vulnerability Recurrence (FVR) analysis isolates specific frontend features that consistently elicit vulnerabilities in Large Language Model (LLM)-generated code. This metric quantifies how frequently a given feature, such as ‘Register New Account’ or ‘Password Reset’, triggers a successful attack across multiple code generations. Results indicate that certain features can achieve 100% vulnerability recurrence in specific LLMs, meaning that every instance of code generated to implement that feature contains a security flaw exploitable through the defined attack vectors. FVR provides granular insight into problematic areas within the frontend, allowing for targeted remediation efforts and improved code generation practices focused on consistently vulnerable features.
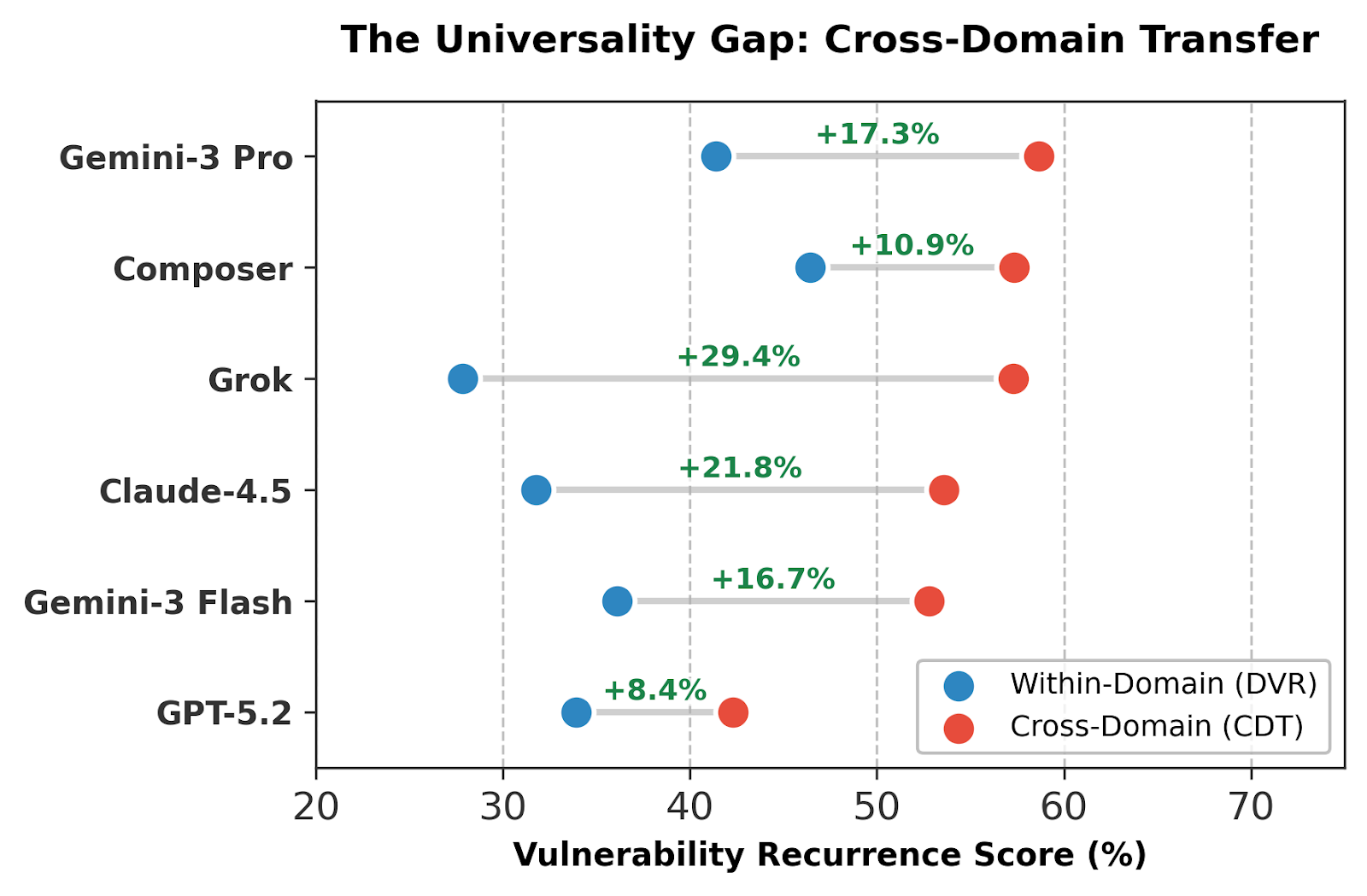
Cross-Domain Transfer (CDT) analysis reveals a consistent propagation of vulnerabilities across disparate software domains. This suggests that identified vulnerabilities are not simply artifacts of specific application contexts, but rather intrinsic weaknesses within the underlying language model itself. Quantified by the ‘Universality Gap’, the CDT metric demonstrates an average increase of +18.3% in vulnerability recurrence when transferring exploits between domains. This indicates that a vulnerability successfully exploited in one domain has an 18.3% higher probability of success in a different, unrelated domain, establishing a baseline for inherent model weaknesses independent of domain-specific implementations.
Application of the FSTab testing framework reveals consistent vulnerability recurrence and transfer across evaluated Large Language Models (LLMs). Specifically, certain software domains, notably E-commerce, exhibit an Attack Success Rate (ASR) reaching 100% when subjected to vulnerability exploits. This indicates a systematic failure of LLM-generated code to maintain security across repeated tests with varied inputs and, critically, when deployed in different application contexts. The observed pattern suggests vulnerabilities are not isolated incidents but are inherent characteristics of the models themselves, rather than being specific to the implemented functionality or target domain.
Beyond Performance: The Imperative of Security Robustness
While benchmarks like WebGenBench and E2EDev serve a valuable purpose in gauging an LLM’s ability to perform tasks correctly, they offer a limited view of the model’s security profile. These datasets primarily focus on functional outputs – whether a model can complete a task – and often lack the adversarial examples or specifically crafted prompts necessary to expose underlying vulnerabilities. Consequently, a model might achieve high scores on these benchmarks while still being susceptible to prompt injection, data leakage, or the generation of harmful content. The narrow scope of these evaluations creates a false sense of security, as they fail to assess the model’s resilience against malicious inputs or its potential to be exploited in real-world applications. A more comprehensive evaluation strategy is therefore crucial, one that actively probes for weaknesses beyond simply verifying functional correctness.
While assessing large language models through model-centric evaluation – focusing solely on individual model responses to crafted prompts – provides a limited view of security, a recent study demonstrates that systemic vulnerabilities remain largely hidden. Researchers found that focusing on individual instances overlooks recurring patterns of failure detectable through frameworks like FSTab, which systematically probes for transferable vulnerabilities across diverse prompts and model architectures. This approach, coupled with novel vulnerability metrics, revealed that models often exhibit consistent weaknesses exploitable in various contexts – failures not apparent when evaluating performance on isolated tasks. The findings suggest that a comprehensive security assessment requires moving beyond isolated evaluations and embracing frameworks capable of uncovering these underlying systemic issues, crucial for building robust and dependable LLM-powered applications.
Current methods for evaluating large language models often prioritize performance on standard benchmarks, overlooking crucial security weaknesses. Recent research demonstrates that these models exhibit recurring vulnerabilities – predictable failure modes exploitable across diverse prompts and applications – and, alarmingly, these vulnerabilities can transfer between models. This necessitates a fundamental shift towards evaluation frameworks specifically designed to identify and measure these systemic flaws, rather than simply assessing functional correctness. Such frameworks must move beyond isolated testing to prioritize the detection of repeatable patterns of failure, enabling developers to proactively address underlying security issues and build more robust and trustworthy LLM-powered applications. The focus needs to be on identifying what consistently breaks, not just that something can break, to foster genuine improvements in model security.
The development of truly trustworthy large language model (LLM) applications demands a fundamental re-evaluation of current assessment strategies. Existing benchmarks often prioritize superficial performance, neglecting the critical need to identify and mitigate underlying security vulnerabilities that could be exploited in real-world deployments. A paradigm shift towards security-focused evaluation isn’t merely about finding flaws; it’s about proactively establishing a robust defense against evolving threats and ensuring consistent, reliable behavior. This necessitates frameworks capable of detecting recurring, transferable weaknesses – those that transcend specific prompts or datasets – rather than isolated incidents. Ultimately, prioritizing security in evaluation is paramount to fostering user confidence and unlocking the full potential of LLMs in sensitive applications, moving beyond functional correctness towards genuine dependability.
The persistence of vulnerability recurrence, as demonstrated in this study of LLM-generated software, echoes a fundamental truth about all complex systems. Just as architectural designs accumulate entropy over time, these models predictably replicate security flaws. Bertrand Russell observed, “The only thing that is constant is change.” This rings true; while the specific vulnerabilities may shift, the tendency toward recurrence remains. The feature-security table, a core concept of this research, essentially maps these patterns of decay, allowing for a kind of proactive ‘refactoring’ of model behavior before exploitable code manifests. It’s a reminder that time doesn’t erase flaws; it reveals them.
The Long Echo
This work reveals a predictable, if disheartening, truth: every architecture lives a life, and the patterns of vulnerability within these large language models are not random noise, but echoes of underlying predispositions. The observed recurrence isn’t a bug in the code generation process, but an inherent characteristic of the systems themselves-a fingerprint left by the training data and model structure. Attempts to patch these vulnerabilities will likely prove temporary; improvements age faster than one can understand them, merely shifting the points of failure rather than eliminating the underlying tendency.
The field now faces a critical juncture. Security evaluations focused solely on surface-level code analysis are becoming increasingly insufficient. A shift toward model-centric assessments-understanding not just what vulnerabilities appear, but why-is paramount. The persistence of these patterns suggests a need to explore the latent space of these models, identifying the core biases that give rise to these flaws.
Ultimately, the challenge isn’t to build perfectly secure code generators, but to accept the inevitable decay and build systems that can adapt and gracefully degrade in the face of persistent, predictable failure. The goal is not immortality, but resilience-a recognition that time is not a metric to be conquered, but the medium in which all systems exist.
Original article: https://arxiv.org/pdf/2602.04894.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- All Skyblazer Armor Locations in Crimson Desert
- One Piece Chapter 1180 Release Date And Where To Read
- How to Get the Sunset Reed Armor Set and Hollow Visage Sword in Crimson Desert
- All Shadow Armor Locations in Crimson Desert
- How to Beat Stonewalker Antiquum at the Gate of Truth in Crimson Desert
- All Golden Greed Armor Locations in Crimson Desert
- All Helfryn Armor Locations in Crimson Desert
- Marni Laser Helm Location & Upgrade in Crimson Desert
- Cassius Morten Armor Set Locations in Crimson Desert
- USD RUB PREDICTION
2026-02-08 19:15