Author: Denis Avetisyan
A new study reveals vulnerabilities in Retrieval-Augmented Generation systems built on graph databases, demonstrating how attackers can reconstruct sensitive knowledge from seemingly secure deployments.

Researchers demonstrate feasible subgraph reconstruction attacks against Graph RAG and propose practical defenses to enhance data security and privacy.
While knowledge graphs enhance relational reasoning in retrieval-augmented generation (RAG) systems, they introduce a novel vulnerability: the potential for adversaries to reconstruct sensitive subgraphs. This paper, ‘Subgraph Reconstruction Attacks on Graph RAG Deployments with Practical Defenses’, demonstrates that existing defenses are often ineffective against targeted extraction attacks, even with simple prompt-based safeguards. We introduce GRASP, a multi-turn attack capable of achieving strong type-faithful subgraph reconstruction-reaching up to 82.9 F1-by reframing extraction as a context-processing task and leveraging a momentum-aware query scheduler. Given the increasing deployment of Graph RAG, how can we proactively design systems resilient to sophisticated knowledge extraction attempts without sacrificing utility?
The Fragility of Memorization: Beyond Scale in Language Models
Conventional Large Language Models, despite their impressive scale, often falter when confronted with tasks demanding extensive knowledge. These models primarily function by identifying patterns within massive datasets, effectively memorizing associations rather than developing a genuine understanding of the underlying concepts. This reliance on sheer parameter count – the number of variables the model learns – creates a brittle knowledge base susceptible to inaccuracies and limited reasoning capabilities. While increasing model size can temporarily improve performance, it doesn’t address the fundamental issue: a lack of structured knowledge representation. Consequently, LLMs can struggle with complex queries requiring inference, contextual awareness, or the integration of diverse information sources, highlighting the need for approaches that prioritize knowledge organization over sheer memorization.
The limitations of traditional Large Language Models in handling complex, knowledge-intensive tasks are being addressed through the development of Graph RAG, a system that structures information as an Entity-Relation Graph. This approach moves beyond simply increasing model parameters and instead focuses on organizing knowledge into interconnected nodes representing entities and the relationships between them. By representing knowledge in this graph format, the system enhances the model’s ability to perform reasoning and contextual awareness; the LLM can then traverse these relationships to find relevant information and draw more informed conclusions. This interconnected structure allows for a deeper understanding of the subject matter, improving the accuracy and relevance of generated responses compared to methods relying solely on statistical patterns within text.
Graph Retrieval-Augmented Generation (RAG) represents a significant evolution in knowledge-intensive tasks by strategically integrating the strengths of Large Language Models (LLMs) with the structured reasoning capabilities of knowledge graphs. Traditional RAG systems often retrieve documents based on keyword similarity, potentially missing crucial contextual relationships; however, Graph RAG instead retrieves information by traversing a graph of entities and their relationships, providing LLMs with more relevant and connected knowledge. This approach allows the LLM to not only access information but also understand how concepts relate to each other, leading to more nuanced, accurate, and insightful responses. Consequently, Graph RAG enhances the LLM’s ability to perform complex reasoning, answer intricate questions, and generate content that reflects a deeper comprehension of the subject matter, ultimately surpassing the limitations of parameter-dependent knowledge storage.
The System Reveals Itself: Knowledge Extraction as Reconstruction
Adversarial prompting techniques can be used to extract sensitive data from Retrieval-Augmented Generation (RAG) systems that utilize knowledge graphs. These attacks function by crafting specific prompts designed to bypass standard security measures and induce the system to reveal information stored within the graph’s relationships and entities. Unlike traditional data breaches, this method doesn’t require direct access to the underlying database; instead, it exploits the system’s natural language processing capabilities to reconstruct knowledge present in the graph. The extracted information can include proprietary details, confidential relationships between entities, and other sensitive data embedded within the knowledge graph structure, presenting a significant risk to data security.
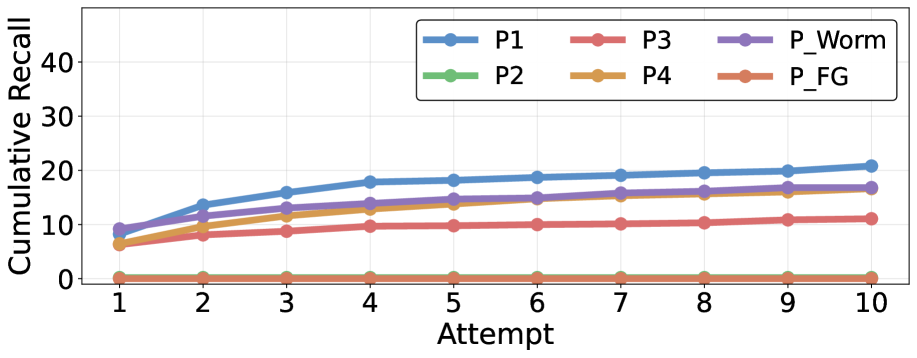
The Graph RAG Reconstruction Attack for Subgraph Profiling (GRASP) focuses on extracting information from one-hop subgraphs within a Graph RAG system. This attack methodology aims to identify relationships directly connecting entities in the knowledge graph. Evaluations of GRASP demonstrate a reconstruction accuracy, measured by F1 score, reaching up to 82.9% on these targeted subgraphs. Performance remains consistently high across different prompt strategies, with RType prompts achieving 82.9% F1 and Naïve prompts yielding an 83.5% F1 score, indicating a robust capability to profile entity relationships.
The Graph RAG Reconstruction Attack for Subgraph Profiling (GRASP) demonstrates a significant vulnerability in Graph RAG systems, achieving up to 82.9% F1 score in reconstructing one-hop subgraphs and revealing relationships between entities. Notably, the attack maintains strong performance regardless of prompt engineering; utilizing both RType prompts (82.9% F1) and simpler, Naïve prompts (83.5% F1) yields comparable results. This indicates a substantial risk of unauthorized data extraction, potentially exposing proprietary information or confidential data embedded within the knowledge graph structure, even with minimal adversarial effort.
Distorting the Signal: Strategies for Defensive Obfuscation
Context Construction Defense is a technique designed to mitigate data extraction attacks by intentionally altering the context provided to the language model. Rather than directly preventing access to data, this defense introduces controlled distortions into the retrieved information before it is processed. This manipulation aims to disrupt the attacker’s ability to accurately reconstruct the original data, effectively creating a barrier to meaningful extraction. The core principle relies on the observation that large language models are highly sensitive to contextual input; by subtly changing this input, the output – and therefore the extracted information – can be significantly altered without necessarily preventing a response. This approach focuses on data integrity rather than strict access control.
ID Alignment, as a defense against knowledge extraction, operates by intentionally collapsing distinct instance identifiers within the data source. This process introduces ambiguity during retrieval, causing the language model to conflate separate entities and generate inconsistent or fabricated information – a phenomenon referred to as hallucination. By obscuring the unique identification of instances, ID Alignment directly hinders the attacker’s ability to accurately reconstruct the original data and reliably extract targeted knowledge, as the model struggles to differentiate between similar but distinct concepts or objects.
Decoy fields represent deliberately inserted, fabricated data points within a knowledge source to disrupt entity linking during knowledge extraction attacks. These fields, appearing as legitimate attributes, lack genuine connections to the core entities and introduce ambiguity into the data. By corrupting attribution, attackers attempting to reconstruct relationships or identify key information are presented with false connections, increasing the likelihood of inaccurate or incomplete extractions. The effectiveness of decoy fields lies in their ability to blend with authentic data, forcing attackers to expend resources validating spurious links and hindering their ability to discern meaningful information from noise.
The Weight of Compliance: Systems and the Illusion of Control
The increasing reliance on large language models (LLMs) presents significant data security challenges, particularly within highly regulated sectors like healthcare. These models, trained on vast datasets, can inadvertently reveal sensitive information if prompted inappropriately, creating substantial risk of non-compliance with laws such as the Health Insurance Portability and Accountability Act (HIPAA). The potential for data extraction isn’t limited to direct breaches; even seemingly innocuous interactions could yield protected health information through subtle cues or statistical inferences learned during training. Consequently, organizations handling confidential patient data must prioritize robust safeguards and carefully evaluate the risks associated with deploying knowledge-augmented LLMs, ensuring adherence to stringent regulatory requirements and maintaining patient trust.
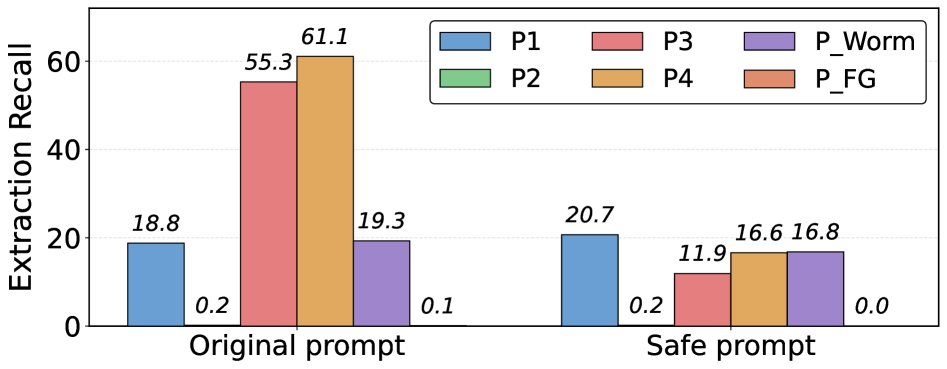
Carefully designed prompts, known as safe prompt engineering, represent a proactive strategy for mitigating the risk of sensitive data leakage from large language models. This approach focuses on structuring user inputs to reinforce pre-defined safety constraints within the model, effectively guiding its responses away from the disclosure of protected health information or other confidential data. By incorporating specific instructions, contextual limitations, and carefully chosen keywords, these prompts can subtly yet powerfully steer the model towards compliant and secure outputs, acting as a first line of defense against unintended data extraction. The technique doesn’t alter the underlying model itself, but rather leverages its existing capabilities by providing it with a safer and more constrained operational space, thus enhancing privacy without sacrificing functionality.
The sustained security of knowledge-augmented large language models (LLMs) hinges on proactive research into defense mechanisms and adversarial training techniques. Current approaches often focus on reactive patching after vulnerabilities are discovered, but a shift towards anticipatory defenses is crucial. Adversarial training, where models are deliberately exposed to crafted inputs designed to elicit undesirable responses, strengthens their resilience. This process simulates real-world attacks, allowing developers to identify and mitigate weaknesses before malicious actors can exploit them. Furthermore, robust defense mechanisms encompass techniques like differential privacy and federated learning, which aim to minimize data leakage and preserve user privacy. Continuous refinement of these strategies, coupled with rigorous evaluation against evolving adversarial tactics, is essential to ensure the long-term trustworthiness and responsible deployment of these increasingly powerful AI systems.
The pursuit of robust retrieval augmented generation inevitably reveals the fragility of the underlying knowledge graphs. This work, detailing subgraph reconstruction attacks, isn’t a revelation of failure, but rather an observation of inevitable evolution. Systems aren’t built to prevent compromise, they are grown to accommodate it. The demonstrated feasibility of these attacks, even against initial defenses, underscores a fundamental truth: long stability isn’t a sign of security, but a symptom of a hidden, evolving vulnerability. As Vinton Cerf once stated, “Any sufficiently advanced technology is indistinguishable from magic.” This ‘magic’ relies on intricate structures, and those structures, like all complex ecosystems, will always be susceptible to unforeseen exploitation and adaptation. The proposed defenses aren’t final solutions, but rather temporary reprieves in a continuous cycle of attack and counter-attack.
What Lies Ahead?
The ease with which targeted subgraphs can be reconstructed from seemingly secure Graph RAG deployments suggests a fundamental truth: every dependency is a promise made to the past. Each vector embedding, each traversed edge, whispers secrets about the original knowledge base. The defenses proposed here, while valuable, merely shift the cost of attack – they do not eliminate the surface. The system will inevitably fix itself, but only after revealing its vulnerabilities, after cycles of probing and patching.
Future work will likely focus on differential privacy mechanisms, attempting to inject noise sufficient to thwart reconstruction without crippling utility. But noise is simply another form of control, and control is an illusion that demands service-level agreements. The more interesting path lies in accepting the inevitability of exposure. Can Graph RAG systems be designed to tolerate partial reconstruction, to gracefully degrade rather than catastrophically fail? To rebuild trust, not by preventing access, but by anticipating and accommodating it?
The field seems fixated on building walls around knowledge. It might be more fruitful to consider the knowledge base not as a fortress, but as a garden. Prune the sensitive information, cultivate redundancy, and accept that some things will always bloom for those who know where to look. The challenge is not to prevent the picking of flowers, but to ensure the garden continues to thrive.
Original article: https://arxiv.org/pdf/2602.06495.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- All Skyblazer Armor Locations in Crimson Desert
- One Piece Chapter 1180 Release Date And Where To Read
- All Shadow Armor Locations in Crimson Desert
- How to Get the Sunset Reed Armor Set and Hollow Visage Sword in Crimson Desert
- Cassius Morten Armor Set Locations in Crimson Desert
- Grime 2 Map Unlock Guide: Find Seals & Fast Travel
- Euphoria Season 3 Release Date, Episode 1 Time, & Weekly Schedule
- New Avatar: The Last Airbender Movie Leaked Online
- Amber Alert Secrets & CDs In Crime Scene Cleaner Act 2
- All Golden Greed Armor Locations in Crimson Desert
2026-02-10 01:56