Author: Denis Avetisyan
A new framework efficiently probes deep learning models to reveal training data origins and hidden security vulnerabilities.
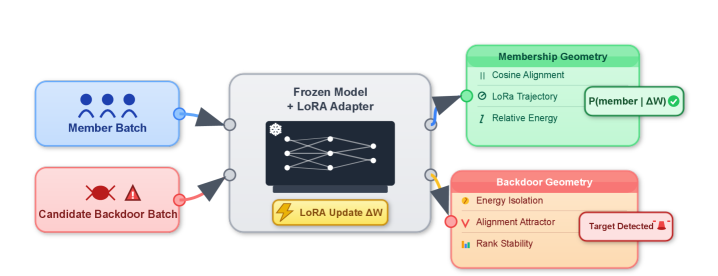
LoRAcle leverages Low-Rank Adapters for post-training auditing to detect membership inference and backdoor attacks.
Despite growing concerns about the security and privacy of deep learning models, current defenses against attacks like data poisoning and membership inference often demand extensive retraining or access to pristine reference models. This work introduces ‘LoRA as Oracle’, a novel framework leveraging low-rank adaptation (LoRA) to efficiently audit deployed models without modification or prior knowledge of training data. By analyzing the distinctive low-rank updates induced by suspicious samples, we demonstrate reliable detection of both backdoor attacks and membership leakage. Could this lightweight, post-training auditing approach offer a practical path towards more trustworthy and secure machine learning systems?
Unveiling Vulnerabilities: The Fragility of Modern AI
Despite their remarkable capabilities, modern deep learning models are proving surprisingly vulnerable to adversarial manipulation. These attacks aren’t characterized by brute-force attempts to overwhelm a system, but rather by carefully crafted inputs – often imperceptible to humans – designed to induce misclassification or unintended behavior. This susceptibility stems from the high dimensionality of the input space and the models’ reliance on statistical correlations rather than genuine understanding. Researchers have demonstrated that even state-of-the-art models can be easily fooled by adding minuscule perturbations to images, altering text by a single character, or exploiting inherent biases in the training data. The implications are significant, extending from compromised security systems and autonomous vehicles to manipulated medical diagnoses and financial predictions, highlighting a critical need for robust defenses and trustworthy artificial intelligence.
Backdoor attacks represent a significant and insidious threat to deep learning systems, subtly compromising model integrity through the embedding of hidden triggers. Techniques like BadNets and Blended demonstrate how attackers can poison a model during training by associating specific, rarely occurring patterns – a small yellow square in an image, or a particular noise pattern – with incorrect classifications. Once deployed, these seemingly innocuous triggers cause the model to misclassify inputs containing them, regardless of the actual content. This allows an attacker to selectively control model behavior, potentially diverting critical systems or manipulating data analysis without raising immediate alarms, as the model performs normally on untampered inputs. The stealth of these attacks – the model appears functional until the trigger is activated – makes detection exceptionally challenging and highlights a critical vulnerability in the deployment of machine learning systems.
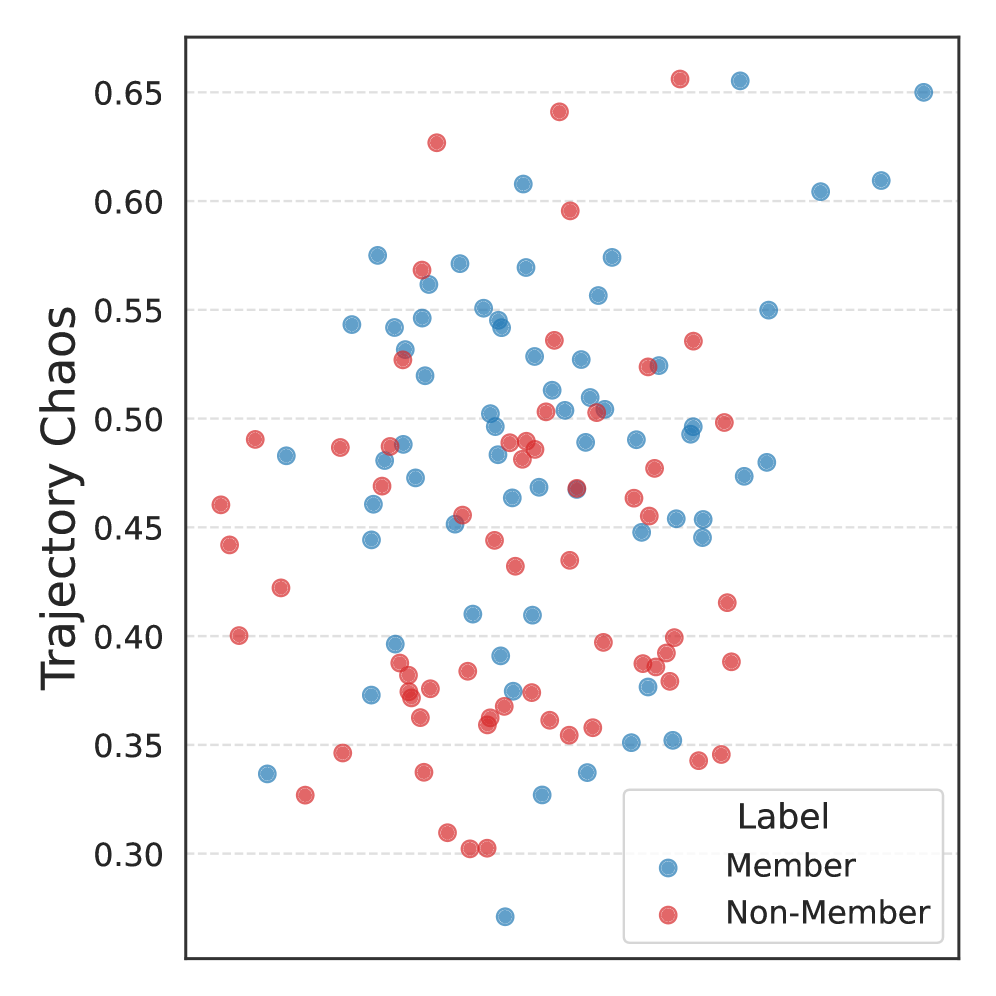
Membership Inference Attacks (MIAs) represent a significant and growing threat to data privacy in the age of machine learning. These attacks don’t attempt to steal the model itself, but rather determine if a specific data point was used during the model’s training process. An attacker, observing a model’s outputs, can infer with surprising accuracy whether an individual’s data contributed to its learning – even without knowing anything about the data itself. This is particularly concerning in sensitive domains like healthcare, where model training often relies on confidential patient records, or finance, where personal financial data is leveraged. Successful MIAs can expose individuals to potential discrimination, identity theft, or other harms, effectively undermining the privacy guarantees expected when data is shared for machine learning purposes. The core principle relies on the fact that models “memorize” aspects of their training data, and subtle patterns in their responses can reveal this memorization to a skilled attacker.
LoRAcle: Auditing Models with Minimal Intrusion
LoRAcle introduces a new methodology for auditing deep learning models by utilizing Low-Rank Adaptation (LoRA). LoRA functions by freezing the pre-trained model weights and introducing trainable low-rank matrices, significantly reducing the number of trainable parameters. This efficiency allows for faster training and reduced computational resource requirements during the auditing process. By analyzing the learned parameters within these LoRA adapters, LoRAcle can effectively probe model behavior without requiring access to the original model weights, providing a non-invasive auditing technique. This approach facilitates the identification of potential vulnerabilities or malicious modifications within the deep learning model.
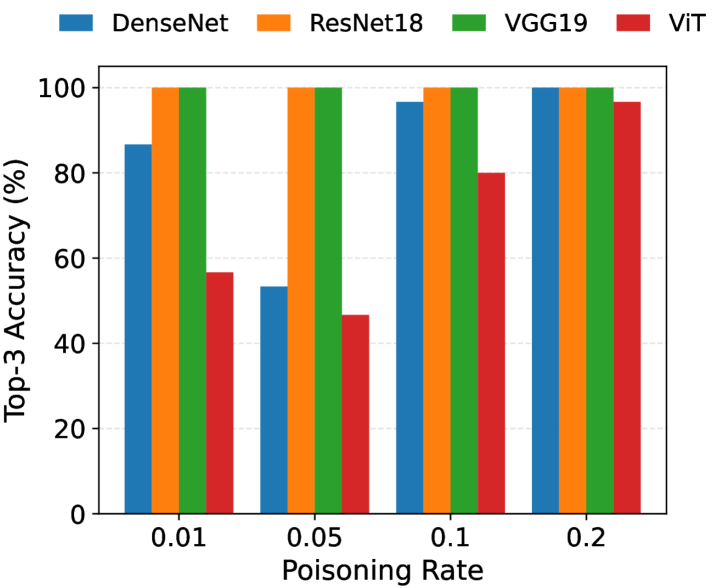
LoRAcle utilizes the analysis of Low-Rank Adaptation (LoRA) adapter behavior to identify potential security vulnerabilities within deep learning models. Specifically, it achieves up to 99% accuracy in Membership Inference attacks on the GTSRB (German Traffic Sign Recognition Benchmark) dataset when used in conjunction with ResNet18 and VGG19 model architectures. This high level of accuracy indicates LoRAcle’s capability to determine whether a specific data point was used during the model’s training phase, suggesting potential data leakage or the presence of backdoors triggered by specific inputs. The framework assesses anomalies in adapter weights and activations to detect these membership inferences.
LoRAcle demonstrates compatibility across common convolutional and transformer-based architectures, including ResNet18, VGG19, Vision Transformer (ViT), and DenseNet. Benchmarking indicates that LoRAcle achieves this architectural flexibility while minimizing resource demands; testing shows reduced GPU power consumption and lower peak memory usage when compared to alternative model auditing defenses. This efficiency is attributed to the parameter-efficient nature of Low-Rank Adaptation (LoRA), which limits the number of trainable parameters and associated computational costs during the auditing process.
Resilient Federated Learning: A Distributed Defense
Federated Learning (FL) enables model training on decentralized datasets residing on edge devices – such as mobile phones or IoT sensors – thereby reducing the need to centralize sensitive data and enhancing privacy. However, this decentralized nature introduces unique security vulnerabilities; while data remains distributed, the shared model updates themselves become potential targets. Specifically, attacks can focus on model poisoning – where malicious participants submit corrupted updates to degrade global model performance – or inference attacks, attempting to reconstruct training data from model parameters or gradients. The broadcast nature of these updates, even if encrypted, creates an attack surface that necessitates robust defense mechanisms beyond standard data encryption.
Several techniques mitigate vulnerabilities in Federated Learning systems. Parameter Pruning reduces the attack surface by selectively removing less important model weights, limiting the information available to malicious participants. Adversarial Training involves augmenting training data with intentionally crafted perturbations, increasing model robustness against adversarial examples designed to compromise performance or extract information. Fully Homomorphic Encryption (FHE) allows computations to be performed directly on encrypted data, preventing access to sensitive information during the training process; however, FHE implementations currently incur significant computational overhead. The effectiveness of each technique depends on the specific threat model and the characteristics of the data and model being used.
The optimization of defense mechanisms within Federated Learning, such as Parameter Pruning, Adversarial Training, and Fully Homomorphic Encryption, frequently leverages Min-Max Optimization principles. This approach frames the problem as a two-player game where one player (the learning algorithm) aims to minimize a loss function, while the other (an adversary simulating attacks) aims to maximize it. The objective is to find a saddle point – a solution where the learning algorithm is robust against the worst-case adversarial perturbations. Formally, this is expressed as \min_{\theta} \max_{\delta} L(\theta, \delta) , where θ represents the model parameters, δ represents the adversarial perturbation, and L is the loss function. Solving this non-convex problem often requires iterative algorithms and careful consideration of convergence rates and stability, particularly in high-dimensional parameter spaces.
Towards Trustworthy AI: A Future of Verifiable Intelligence
LoRAcle represents a significant step towards building demonstrably trustworthy artificial intelligence systems through a novel combination of techniques. By integrating Low-Rank Adaptation (LoRA) with resilient Federated Learning, the framework allows for the verification of AI models without compromising performance or privacy. This approach enables a detailed analysis of model behavior, revealing potential vulnerabilities like backdoor attacks that could otherwise go undetected. Crucially, LoRAcle doesn’t simply identify these weaknesses; its integration with Federated Learning allows for collaborative mitigation across distributed datasets, enhancing the robustness of AI deployments. The result is a pathway to verifiable AI, fostering confidence in sensitive applications where transparency and reliability are paramount, and ultimately broadening the scope of responsible AI adoption.
The increasing reliance on artificial intelligence within critical sectors like healthcare and finance necessitates a fundamental shift towards systems that are both auditable and robust. Unlike traditional ‘black box’ models, where decision-making processes remain opaque, trustworthy AI demands transparency – the ability to trace and verify how a conclusion was reached. This isn’t merely about understanding what an AI predicts, but why it made that prediction, enabling human oversight and accountability. Robustness, meanwhile, ensures consistent and reliable performance even when confronted with unexpected or adversarial inputs, protecting against manipulation and error in high-stakes scenarios. Without these qualities, public trust erodes, hindering the potential of AI to revolutionize these sensitive domains and deliver genuine benefit.
Recent advancements in artificial intelligence security demonstrate a pathway toward more dependable and trustworthy systems. LoRAcle, a novel detection method, has achieved a landmark result: 100% Top-3 Backdoor Detection Accuracy when tested on the GTSRB dataset using both ResNet18 and VGG19 neural network architectures. This signifies LoRAcle’s ability to consistently identify even subtle, hidden manipulations designed to compromise AI decision-making. Such high accuracy is not merely a technical achievement; it directly addresses a critical barrier to AI adoption in sectors where reliability is paramount, such as healthcare diagnostics and financial modeling. By bolstering confidence in AI’s integrity, LoRAcle paves the way for broader implementation and acceptance of these powerful technologies, promising benefits across numerous fields.
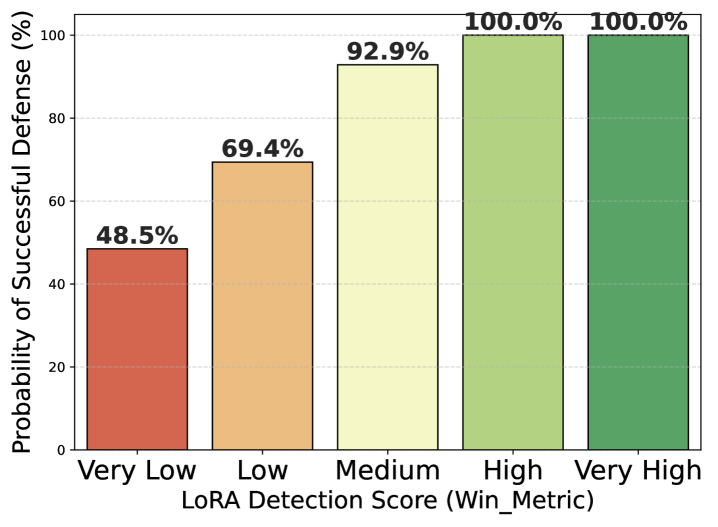
The pursuit of model security, as detailed in this work regarding LoRAcle and the detection of data provenance, mirrors a fundamental tenet of efficient system design. Ken Thompson observed, “Debugging is twice as hard as writing the code in the first place. Therefore, if you write the code as cleverly as possible, you are, by definition, not smart enough to debug it.” This sentiment extends to model auditing; overly complex models obfuscate vulnerabilities, making post-training analysis – like identifying membership inference or backdoor attacks – significantly more challenging. LoRAcle’s strength lies in its lightweight approach, prioritizing clarity and ease of inspection over sheer model capacity. It’s a testament to the idea that effective security isn’t achieved through complexity, but through a deliberate reduction of it.
Further Horizons
The efficiency of LoRAcle, while notable, merely shifts the locus of concern. Detection, however lightweight, remains asymptotic to perfect security. The framework illuminates vulnerabilities, but does not, by its nature, resolve them. Future iterations must address the fundamental tension: probing for weakness inevitably introduces new avenues for exploitation. This is not a failing, but a property of the system.
Current work assumes a static threat model. A more nuanced approach will require dynamic auditing-continuous assessment that adapts to evolving adversarial strategies. LoRA’s parameter-efficient nature presents an opportunity, but also a constraint. The very reduction in complexity that makes it practical may limit its capacity to detect subtle, high-dimensional attacks. Clarity is the minimum viable kindness, but sometimes the signal is lost in the noise of simplicity.
Ultimately, the field must move beyond reactive detection. Proactive defenses-techniques that build robustness directly into the fine-tuning process-represent a more sustainable path. The question is not simply whether a model is compromised, but how to build models that resist compromise from the outset. This is not a technical problem alone; it is a matter of acknowledging inherent limitations.
Original article: https://arxiv.org/pdf/2601.11207.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- All Skyblazer Armor Locations in Crimson Desert
- One Piece Chapter 1180 Release Date And Where To Read
- How to Get the Sunset Reed Armor Set and Hollow Visage Sword in Crimson Desert
- All Shadow Armor Locations in Crimson Desert
- All Golden Greed Armor Locations in Crimson Desert
- How to Beat Stonewalker Antiquum at the Gate of Truth in Crimson Desert
- Cassius Morten Armor Set Locations in Crimson Desert
- Grime 2 Map Unlock Guide: Find Seals & Fast Travel
- USD RUB PREDICTION
- Marni Laser Helm Location & Upgrade in Crimson Desert
2026-01-19 19:41