Author: Denis Avetisyan
A new study shows that surprisingly compact language models can effectively identify multiple issues hidden within seemingly simple code changes.
Researchers demonstrate effective multi-label classification of semantic concerns in code commits using small language models as a cost-efficient alternative to larger models.
While version control systems encourage atomic commits focused on single goals, developers frequently bundle multiple, tangled concerns into single changesets, hindering maintainability. This paper, ‘Detecting Multiple Semantic Concerns in Tangled Code Commits’, addresses this challenge by framing multi-concern detection as a multi-label classification problem and demonstrating the feasibility of using small language models (SLMs) for this task. Empirical results reveal that a fine-tuned 14B-parameter SLM achieves competitive performance with state-of-the-art large language models for single-concern commits and remains usable for up to three concerns, with commit messages significantly improving accuracy. Could this approach offer a practical, cost-effective path towards automatically identifying and refactoring tangled commits to improve code quality and developer productivity?
The Inevitable Entanglement: A History of Tangled Commits
Contemporary software engineering practices prioritize frequent code commits to facilitate collaboration and rapid iteration. However, this approach frequently results in what are termed ‘Tangled Commits’ – single commits that address multiple, logically distinct changes. Instead of isolating a specific feature implementation or bug fix, developers often bundle improvements to documentation, refactoring, and diverse functionality within a single commit. While seemingly efficient, this practice obscures the true scope of each alteration, making it difficult to understand the precise motivation and impact of any given change. The resulting entanglement complicates subsequent code reviews, hinders effective debugging, and ultimately contributes to the accumulation of technical debt, as the historical record becomes a complex web of interwoven modifications rather than a clear, traceable series of improvements.
The practice of bundling multiple, disparate changes into single commits creates significant challenges throughout the software lifecycle. Code reviews become laborious, as assessors must dissect interwoven modifications to identify potential issues, increasing the risk of overlooking critical flaws. Debugging is similarly hampered; tracing the origin of a bug becomes a complex exercise when a single commit addresses several unrelated concerns. More insidiously, this practice accrues technical debt – the implied cost of rework caused by choosing an easy solution now instead of a better approach that would take longer. Over time, this debt compounds, making future development slower, more expensive, and more prone to errors as the codebase becomes increasingly difficult to understand and modify.
Effective software maintenance hinges on comprehending why a change was made, not simply what was altered, yet current commit analysis tools typically operate at a syntactic level, failing to identify distinct ‘Semantic Concerns’ within a single commit. This lack of granularity obscures the developer’s original intent, making it difficult to accurately assess the impact of changes, locate the source of bugs, or refactor code with confidence. Consequently, even seemingly small modifications can introduce unintended consequences and contribute to escalating technical debt, as the true purpose of individual code segments remains obscured within a mass of bundled alterations. Addressing this limitation requires new techniques capable of discerning the underlying semantic meaning of each change, allowing for a more precise understanding of the codebase’s evolution and facilitating long-term maintainability.
Discerning Intent: A Multi-Label Approach to Commit Analysis
Multi-label classification addresses the complexity of software commits which often involve multiple, overlapping concerns beyond a single, primary function. Unlike traditional single-label classification, this approach allows for the assignment of multiple labels to a single commit, reflecting the diverse semantic changes implemented. These labels can represent areas such as bug fixes, feature implementations, performance optimizations, security enhancements, or documentation updates. By simultaneously identifying all relevant concerns within a commit, multi-label classification provides a more nuanced and comprehensive understanding of the changes, enabling more effective analysis and management of the codebase.
Models utilize both the ‘Code Diff’ and ‘Commit Message’ to establish correlations between implemented code modifications and the developer’s stated purpose. The ‘Code Diff’ provides a detailed record of specific lines added, removed, or modified, while the ‘Commit Message’ offers a natural language description of the change. By training on paired data of code differences and associated commit messages, these models learn to identify patterns – specific code constructs, keywords, or structural changes – that reliably indicate particular intents, such as bug fixes, feature additions, performance optimizations, or refactoring efforts. This approach enables automated intent recognition by analyzing new commits based on the learned associations.
Automated analysis of commit data – specifically the association of code diffs with commit message intent – generates valuable metadata that streamlines development processes. This metadata facilitates more efficient code reviews by providing reviewers with immediate insight into the purpose of changes. Furthermore, it enables more targeted testing strategies, allowing quality assurance efforts to focus on areas affected by specific intents. Recent studies demonstrate that fine-tuned small language models (SLMs) can achieve performance levels competitive with larger language models (LLMs) in detecting these semantic concerns, particularly within commits exhibiting up to three distinct concerns. This suggests SLMs offer a computationally efficient alternative for integrating intent detection into existing development workflows.

The Performance Trade-off: Balancing Model Size and Accuracy
The deployment of Large Language Models (LLMs) for tasks like commit classification presents significant computational challenges. LLMs require substantial processing power and memory, leading to high inference costs. This computational demand directly translates into increased ‘Inference Latency’ – the time taken to process a single request. Unacceptable latency can severely hinder developer workflows and integration into continuous integration/continuous delivery (CI/CD) pipelines, making real-time or near real-time commit analysis impractical. The resource requirements of LLMs often necessitate specialized hardware, such as GPUs, further increasing the total cost of ownership and operational complexity when compared to smaller models.
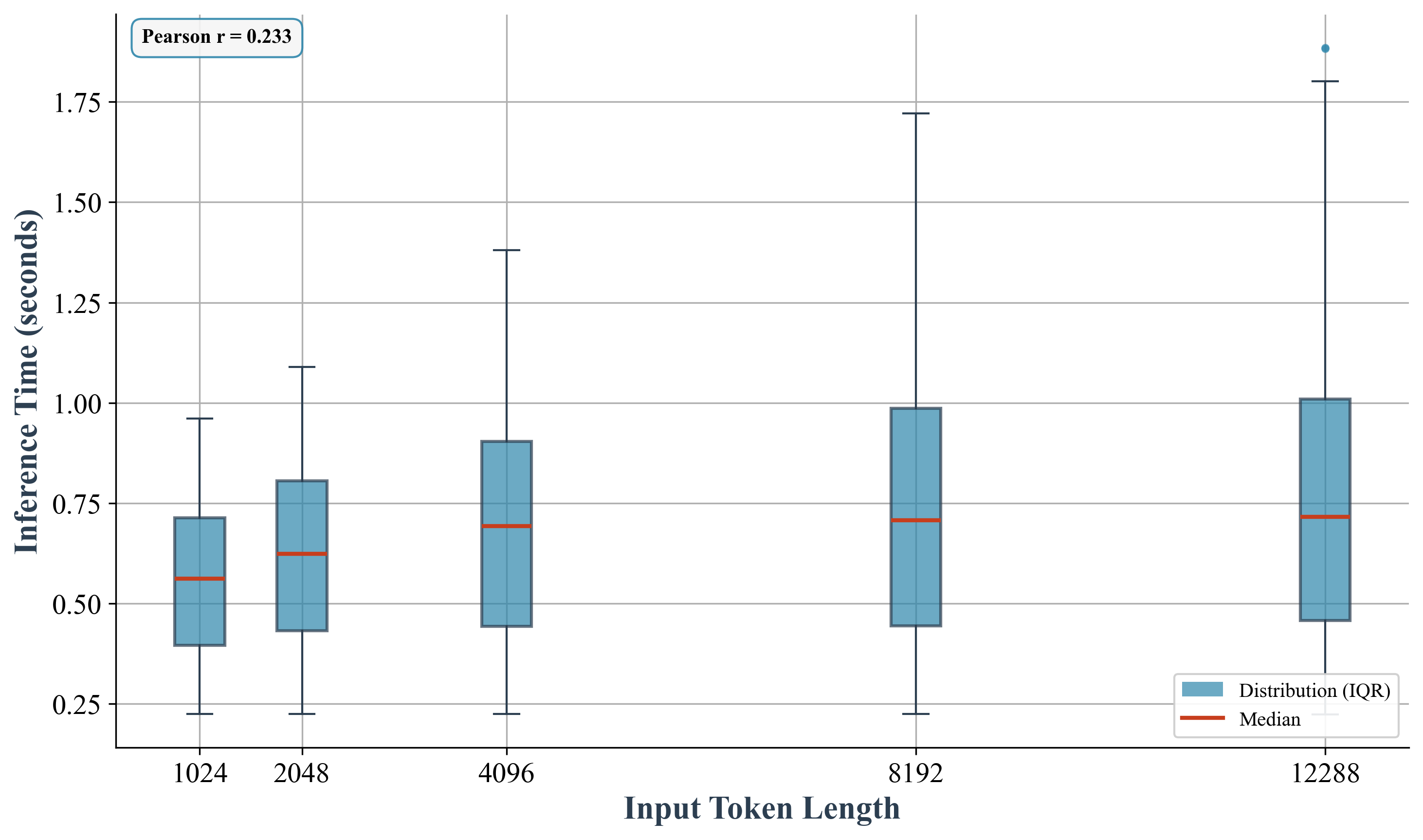
Small Language Models (SLMs) present a viable alternative to larger models for tasks like commit classification due to their reduced computational demands and faster inference speeds. However, SLMs operate with a limited ‘Token Budget’, which defines the maximum input sequence length they can process. This constraint necessitates careful consideration of input size, as exceeding the token limit results in truncation or rejection of the input. While SLMs generally exhibit lower absolute accuracy compared to larger models, they offer a favorable trade-off between performance and efficiency, particularly when deployed in resource-constrained environments or applications requiring low latency.
Header-preserving truncation is a technique used to address the token budget limitations of Small Language Models (SLMs) when applied to code diff classification. This method intelligently shortens code differences while retaining essential contextual information, such as file headers and function signatures. Our research indicates that SLMs, when fine-tuned with this technique, achieve a Hamming Loss between 0.14 and 0.15, demonstrating performance competitive with the larger GPT-4.1 model. Furthermore, the observed effect size, ranging from 0.6 to 0.8 (A12), signifies a substantial performance improvement over base, un-tuned SLMs, highlighting the efficacy of fine-tuning in maximizing the utility of SLMs for this task.
Beyond Pattern Recognition: Enriching Classification with Context
Modern multi-label classification systems benefit substantially from techniques that move beyond simple input-output mappings. Methods like Chain-of-Thought Prompting and Retrieval-Augmented Generation enhance accuracy by equipping models with access to more comprehensive contextual information. Rather than directly assigning labels, these approaches encourage the model to first ‘reason’ through the available data – be it code changes or associated commit messages – and then formulate a classification based on that internal process. Retrieval-Augmented Generation, in particular, allows the model to consult a broader knowledge base, effectively expanding its understanding of the task at hand. This richer context enables the identification of nuanced relationships and subtle semantic cues, leading to a more precise and insightful categorization compared to systems relying solely on immediate input features.
Advanced classification techniques empower models to move beyond simple pattern recognition and engage in a form of reasoning regarding code changes. By considering the broader context of a commit – not just the code itself, but also the accompanying message and potentially related historical data – the model can discern nuanced semantic concerns. This ability to ‘reason’ allows it to identify subtle implications within the changes, such as potential side effects, design considerations, or adherence to specific coding standards, which might be overlooked by traditional methods. The result is a more sophisticated understanding of the developer’s intent, ultimately leading to more accurate classification and improved code quality assessments.
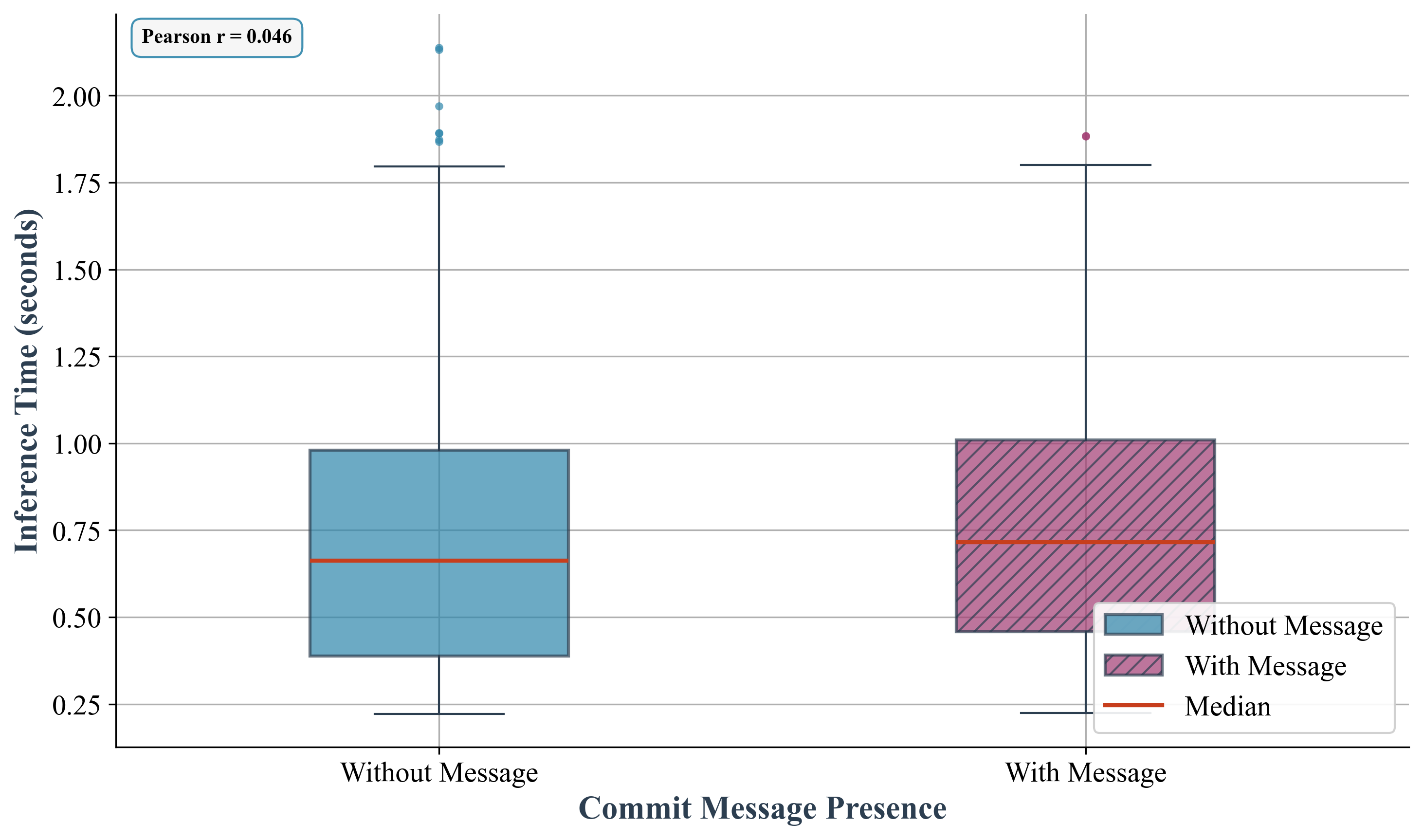
Enhanced commit classification directly translates to improvements in both code quality and long-term maintainability. Recent studies demonstrate that a more nuanced understanding of a developer’s intent-achieved through techniques that provide richer contextual information-yields measurable benefits. Specifically, researchers observed a consistent reduction in Hamming Loss, a metric for evaluating multi-label classification accuracy, when commit messages were incorporated into the analysis across all models tested. Importantly, this increase in accuracy came with a negligible impact on inference latency, suggesting that these advanced techniques can be integrated into existing workflows without significant performance overhead. This granular level of understanding allows for more precise code reviews, better bug detection, and ultimately, a more robust and easily maintained codebase.
Towards Atomic Commits: A Future of Clear History and Efficient Evolution
Automated commit analysis tools are increasingly employed to guide developers towards crafting atomic commits – changes that encapsulate a single, logical concern. These tools scrutinize proposed changes, identifying instances where multiple, unrelated modifications are bundled together within a single commit. By flagging such instances, the analysis encourages developers to decompose larger changes into smaller, more focused units. This practice not only simplifies code review but also dramatically improves the clarity and maintainability of the project’s history, enabling more efficient debugging and collaboration. The resulting codebase benefits from a streamlined version control log, where each commit represents a discrete, easily understandable alteration, fostering a more robust and evolvable system.
Adhering to the Conventional Commit Specification provides a standardized approach to crafting commit messages, significantly enhancing the clarity and maintainability of a project’s history. This specification doesn’t merely dictate how a commit message is written, but establishes a defined structure – utilizing prefixes like ‘feat’, ‘fix’, ‘docs’, and ‘refactor’ – to immediately convey the purpose of each change. By consistently employing this format, development teams create a readily understandable log of modifications, streamlining code reviews, debugging efforts, and automated release processes. This structured approach transforms commit history from a potentially opaque record into a valuable source of information about the project’s evolution, fostering collaboration and reducing cognitive load for all contributors.
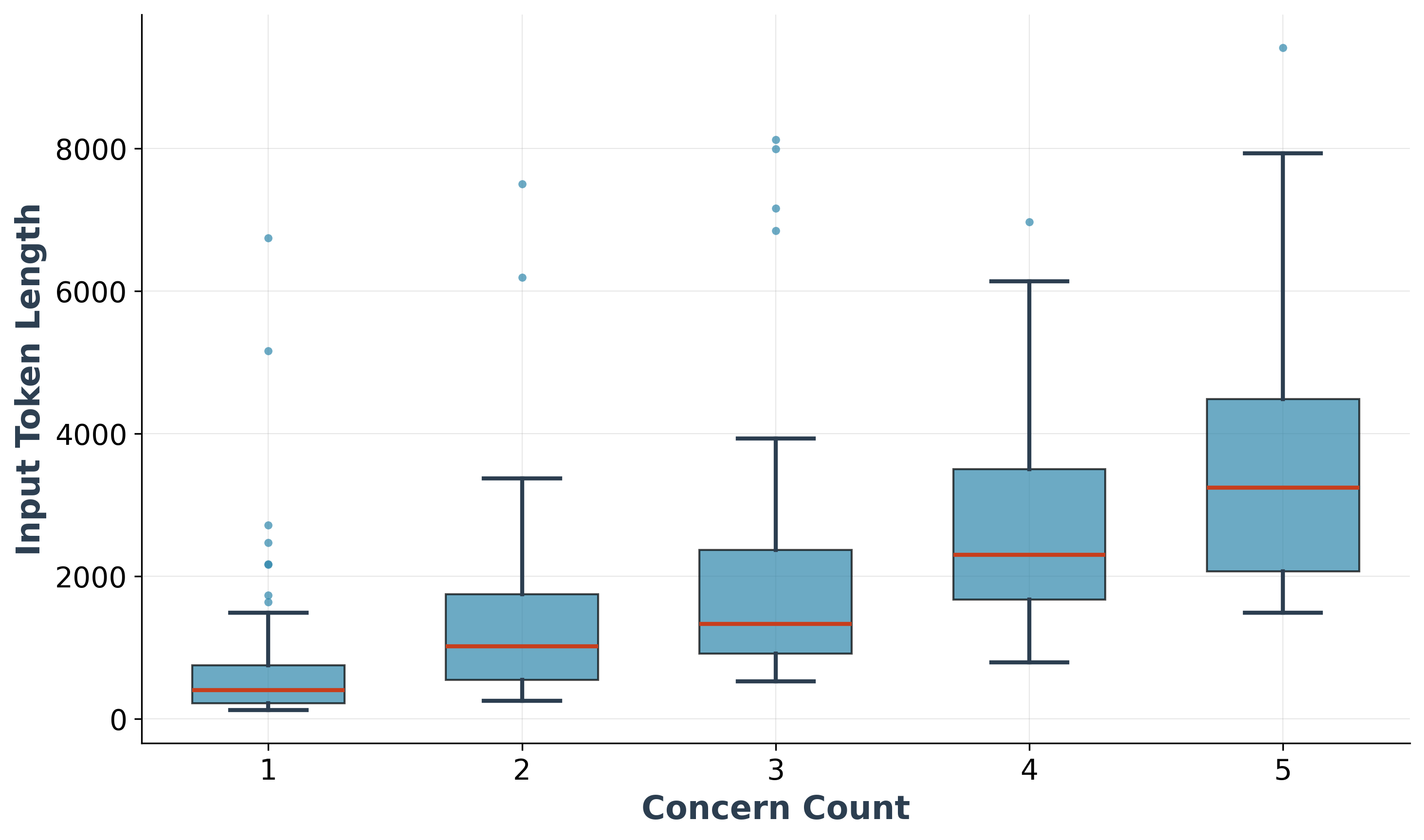
Version control systems offer maximum benefit when commit history reflects focused, singular changes; research demonstrates a clear link between commit complexity and system performance. A recent study revealed a strong positive correlation (r=0.81) between the number of distinct concerns addressed within a single commit and increased inference latency. This suggests that bundling multiple changes into one commit significantly impacts the time required for automated processes, such as testing and deployment. By adopting principles like atomic commits – where each commit addresses a single, well-defined issue – development teams can cultivate a codebase that is demonstrably easier to understand, debug, and extend, ultimately streamlining the entire software lifecycle and improving overall system efficiency.

The pursuit of discerning semantic concerns within code commits, as detailed in this study, echoes a fundamental principle of system longevity. Every commit, effectively a snapshot of evolving intent, contributes to the overall architecture-and tangled commits represent a form of entropy. As John von Neumann observed, “The best mode of attack is to anticipate the opponent’s moves.” In this context, proactively identifying multiple semantic concerns-rather than reacting to emergent issues-becomes a preemptive strike against technical debt. The demonstrated efficacy of small language models in this task suggests a pragmatic approach to maintaining system health, allowing for a more graceful aging process by addressing concerns before they accumulate into significant burdens. This aligns with the principle that delaying fixes is a tax on ambition; early detection, enabled by SLMs, minimizes that tax.
What Lies Ahead?
The demonstrated efficacy of small language models in discerning semantic concerns within code commits offers a reprieve, not a resolution. Every failure is a signal from time; the tangle persists even as the tools to map it become more refined. The current work identifies a practical approach, but the underlying problem-the accumulation of implicit intent within code-remains. Future investigation must address not simply what a commit changes, but why-a question that demands a deeper understanding of developer cognition and the evolution of software design.
The limitations inherent in multi-label classification also warrant further scrutiny. Assigning discrete labels to nuanced concerns is, at best, a temporary accommodation. The true nature of code is rarely so neatly categorized. The field should explore methods that embrace ambiguity and allow for the representation of overlapping or conflicting intents. Refactoring is a dialogue with the past; better tools will not erase it, but will allow for a more informed conversation.
Ultimately, the success of such models will be measured not by their accuracy in labeling existing commits, but by their ability to prevent the creation of tangled code in the first place. Shifting the focus from detection to prevention represents a fundamental re-evaluation of software development practices-a move toward a more mindful and sustainable approach to building complex systems.
Original article: https://arxiv.org/pdf/2601.21298.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- All Shadow Armor Locations in Crimson Desert
- How to Get the Sunset Reed Armor Set and Hollow Visage Sword in Crimson Desert
- Best Bows in Crimson Desert
- All Skyblazer Armor Locations in Crimson Desert
- All Golden Greed Armor Locations in Crimson Desert
- Marni Laser Helm Location & Upgrade in Crimson Desert
- All Helfryn Armor Locations in Crimson Desert
- Wings of Iron Walkthrough in Crimson Desert
- How to Craft the Elegant Carmine Armor in Crimson Desert
- Keeping Large AI Models Connected Through Network Chaos
2026-01-31 22:58