Author: Denis Avetisyan
Researchers have developed a new generative model that replaces discrete quantization with a continuous Principal Component Analysis layer, offering improved performance and interpretability.
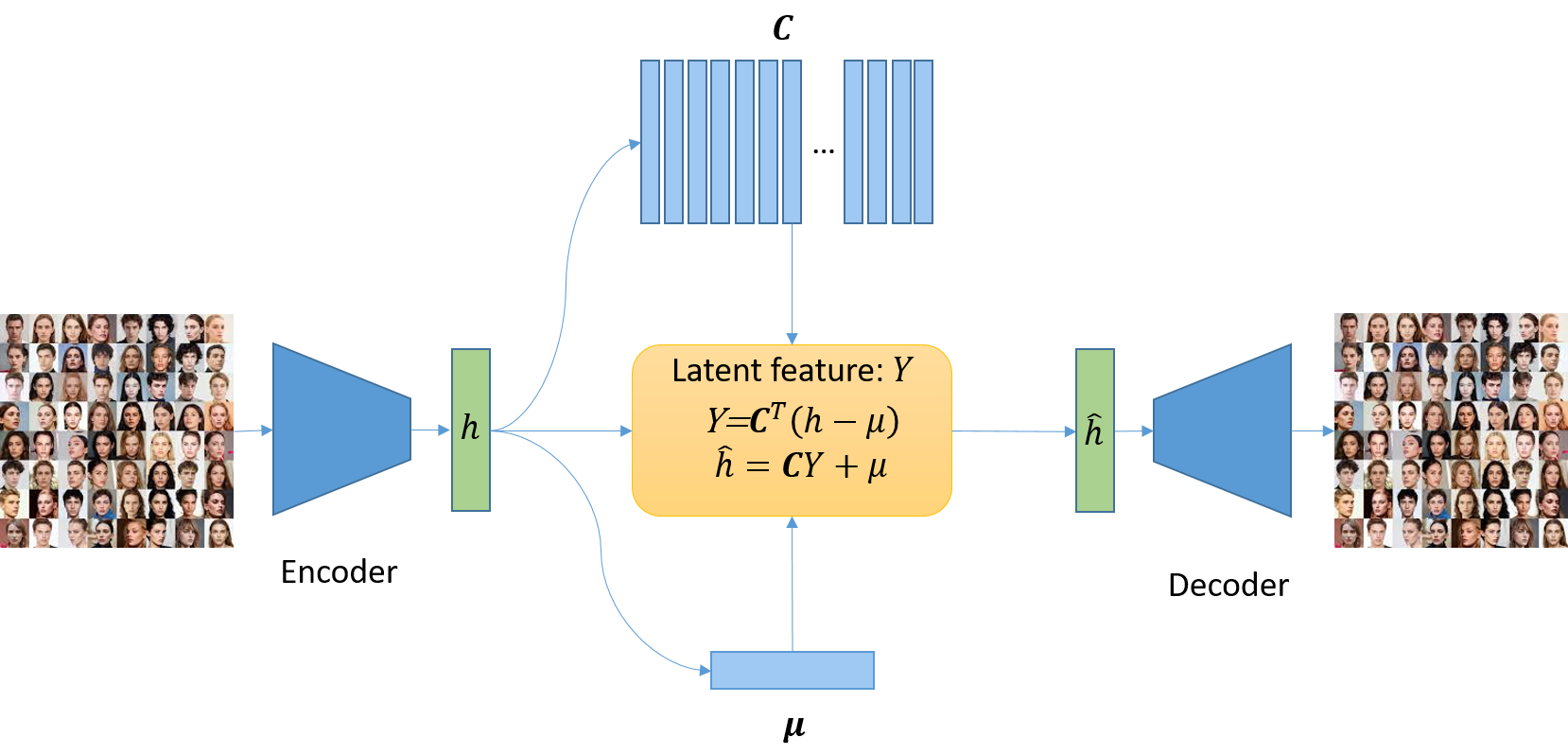
PCA-VAE introduces a differentiable subspace quantization method that avoids codebook collapse and enhances reconstruction quality in variational autoencoders.
Vector quantization offers efficient latent representations but introduces non-differentiability and instability in autoencoders. This limitation motivates the work presented in ‘PCA-VAE: Differentiable Subspace Quantization without Codebook Collapse’, which proposes replacing discrete vector quantization with a continuous, differentiable principal component analysis (PCA) bottleneck. The resulting PCA-VAE learns an orthogonal, variance-ordered latent basis that exceeds the performance of VQ-GAN and SimVQ on CelebAHQ while achieving greater bit efficiency and improved interpretability. Could this approach-grounded in established linear algebra-offer a fundamentally more stable and semantically structured pathway for future generative models beyond vector quantization?
The Inevitable Compression: Navigating Discrete Latent Spaces
Generative models, pivotal in creating realistic images, audio, and text, are increasingly leveraging discrete latent spaces achieved through Vector Quantization (VQ) for enhanced efficiency. Rather than representing data with continuous values, VQ compresses information into a finite set of learned embeddings – a ‘codebook’ – allowing models to operate with discrete tokens. This discretization significantly reduces computational demands and memory usage, particularly crucial for scaling to high-resolution outputs and complex datasets. By forcing the model to choose from a limited vocabulary of representations, VQ encourages the development of more structured and interpretable latent spaces, ultimately streamlining the generative process and facilitating more focused data manipulation. The technique has become a cornerstone in architectures like VQ-VAE and VQ-GAN, demonstrating its power in balancing representational capacity with computational feasibility.
Standard Vector Quantization (VQ), while computationally efficient for creating discrete latent spaces in generative models, frequently suffers from a phenomenon termed ‘Codebook Collapse’. This occurs when the learned codebook-the set of representative vectors used to approximate data-becomes overly concentrated, with many vectors converging to similar or identical values. Consequently, the model loses the ability to distinctly represent diverse features within the data, severely limiting its expressiveness and ultimately degrading the quality of generated outputs. Essentially, the latent space, intended to provide a rich and varied representation, becomes functionally diminished, hindering the model’s capacity for complex data reconstruction and novel content creation.
The phenomenon of codebook collapse significantly constrains a generative model’s capacity to leverage the full potential of its discrete latent space, ultimately diminishing the quality of generated outputs. When a codebook collapses, a disproportionate number of learned latent vectors converge on a small subset of codebook entries, effectively reducing the dimensionality of the representational capacity. This bottleneck restricts the model’s ability to capture subtle variations in the data and express nuanced features during the generation process. Consequently, generated samples often exhibit a lack of detail, reduced diversity, and a general loss of fidelity compared to the training data – a clear indication that the model isn’t fully utilizing the information encoded within its supposedly expansive latent space. Addressing this limitation is crucial for unlocking the full creative power of vector-quantized generative models.
![PCA-VAE achieves superior reconstruction performance, as evidenced by normalized metrics (higher values are better) compared to VQGAN[23], SimVQ[27], VQ-VAE[17], and a standard VAE[18], all utilizing <span class="katex-eq" data-katex-display="false">16 \times 16</span> latents and 8,912 codebook tokens.](https://arxiv.org/html/2602.18904v1/images/radar.png)
Bridging the Divide: Introducing Continuous Latent Spaces
PCA-VAE departs from traditional Variational Autoencoder (VAE) architectures by substituting the Vector Quantization (VQ) layer with an online Principal Component Analysis (PCA) module. Standard VAEs often employ discrete latent spaces through VQ, which can introduce limitations in gradient flow and representation smoothness. PCA, in contrast, provides a continuous latent representation by projecting the data onto a lower-dimensional subspace defined by the principal components. The “online” aspect indicates that the PCA module dynamically adapts to the incoming data stream during training, calculating and updating the principal components incrementally rather than relying on a pre-computed static transformation. This integration allows PCA-VAE to represent data with a smoothly evolving latent space, potentially improving both reconstruction quality and generalization performance.
Traditional vector-quantized Variational Autoencoders (VAEs) utilize a discrete latent space, which introduces limitations due to the inherent information loss during quantization and the creation of artificial boundaries between latent codes. PCA-VAE addresses this by replacing the discrete layer with an online Principal Component Analysis (PCA) module, establishing a continuous latent space. This allows for smoother transitions between encoded data points, facilitating more effective data generation and manipulation. The resulting latent vectors are not restricted to a finite set of codes, preventing information bottlenecks and enabling the model to capture subtle variations in the input data with greater fidelity. This continuity is crucial for applications requiring nuanced representations and avoids the discontinuities often associated with discrete latent spaces.
PCA-VAE utilizes Principal Component Analysis (PCA) to identify and retain the directions of greatest variance within the input data. This is achieved by projecting the data onto a lower-dimensional subspace spanned by the principal components – eigenvectors derived from the covariance matrix of the data. By focusing on these components, PCA-VAE effectively discards dimensions with minimal variance, reducing dimensionality while preserving the most salient information. The number of retained principal components directly controls the degree of dimensionality reduction and the trade-off between data compression and reconstruction fidelity. This process ensures that the latent space representation prioritizes the features contributing most to the overall data distribution, enabling efficient data encoding and improved generalization performance.
PCA-VAE demonstrates enhanced data compression capabilities by achieving reconstruction quality comparable to, or exceeding that of, current state-of-the-art vector-quantized Variational Autoencoders while utilizing significantly fewer latent bits. Specifically, PCA-VAE achieves this performance with a reduction of one to two orders of magnitude in the number of bits required to represent the latent space. This improvement in information efficiency allows for more compact data representation without compromising reconstruction fidelity, representing a substantial advancement in model size and potential deployment scenarios.

Evidence of Performance: Validation on CelebA-HQ
The CelebA-HQ dataset, utilized for PCA-VAE evaluation, comprises 30,000 high-resolution (1024×1024) face images. This dataset is widely recognized within the generative modeling community as a challenging benchmark due to its high fidelity and diversity of facial features, poses, and expressions. Its large scale and image quality allow for rigorous assessment of a model’s ability to generate realistic and detailed facial images, as well as its capacity for capturing nuanced variations in human appearance. Evaluation on CelebA-HQ provides a standardized comparison point against other state-of-the-art generative models, facilitating objective performance analysis.
Performance of the PCA-VAE was quantitatively assessed on the CelebA-HQ dataset using the rFID, SSIM, and LPIPS metrics. The rFID metric, which evaluates the fidelity and diversity of generated images, demonstrated that the PCA-VAE achieved results comparable to or exceeding those of established generative models. Structural Similarity Index (SSIM) scores indicated a high degree of perceptual similarity between reconstructed and original images, confirming the model’s ability to preserve key visual features. Finally, the Learned Perceptual Image Patch Similarity (LPIPS) metric, sensitive to perceptual differences, further validated the PCA-VAE’s competitive performance in generating realistic and high-quality facial images.
PCA-VAE demonstrates reconstruction performance on par with Vector Quantized (VQ)-based generative models, but with significantly reduced data requirements for latent space representation. Quantitative evaluation reveals that PCA-VAE achieves comparable scores on standard image quality metrics – including rFID, SSIM, and LPIPS – while utilizing a latent space that is 10 to 100 times smaller in bit representation than those employed by VQ-VAE and similar techniques. This reduction in latent dimensionality contributes to both computational efficiency and decreased storage requirements without sacrificing reconstruction fidelity, representing a key advantage of the proposed method.
The Principal Component Analysis (PCA) basis vectors within the PCA-VAE are updated incrementally during training via an online learning process utilizing Oja’s Rule. This stochastic gradient descent-based learning rule, \Delta w_{i} = \eta (x - \hat{x}) x_{i} , where η is the learning rate, x is the input data, and x_{i} represents the i-th principal component, allows for adaptation to each training sample without requiring full batch statistics. This approach avoids the computational cost and memory requirements of batch PCA while maintaining stability through continuous, small adjustments to the basis vectors, enabling efficient training even with high-dimensional data like the CelebA-HQ dataset.
Geometric γ-fade is a technique implemented to improve the training stability of the PCA-VAE by providing a robust running-mean centering mechanism. This method calculates a geometrically decayed average of the PCA basis vectors, effectively smoothing the updates and preventing drastic shifts in the latent space. The decay factor, γ, controls the rate at which older basis vectors influence the current mean, mitigating the impact of noisy or outlier data points during each training iteration. This running-mean centering stabilizes the learning process, particularly when employing Oja’s Rule for online PCA updates, and contributes to more consistent and reliable performance across training epochs.

Beyond the Immediate: Implications and Future Directions
The Principal Component Analysis Variational Autoencoder (PCA-VAE) distinguishes itself through a continuous latent space, a key advancement over traditional generative models that often rely on discrete representations. This continuity allows for smoother transitions between generated samples and facilitates precise control over the generative process; rather than selecting from a limited set of pre-defined features, the model can navigate a spectrum of possibilities. Consequently, researchers gain enhanced interpretability, as specific directions within this latent space correspond to meaningful variations in the generated output – for example, subtly altering an image’s pose or expression. This nuanced control not only improves the quality and realism of generated content but also opens avenues for targeted edits and explorations within the data manifold, representing a significant step towards more intuitive and powerful generative systems.
The core principles underpinning the PCA-VAE method aren’t intrinsically limited to visual data; its adaptability extends to a broader range of modalities. By representing data as a continuous latent space, the technique can be readily applied to sequential data like audio waveforms or the discrete symbols of text. Instead of pixels, the encoding and decoding processes would operate on audio samples or word embeddings, respectively. This flexibility opens opportunities for generating novel audio compositions, crafting coherent textual narratives, or even translating between different data types – for example, creating music from textual descriptions. The method’s success in image generation suggests a promising pathway towards more versatile and unified generative modeling across diverse data landscapes, potentially streamlining the development of AI capable of handling multiple sensory inputs and outputs.
The principles underlying this work demonstrate a compelling compatibility with Latent Diffusion Models (LDMs), a leading paradigm in generative AI. By integrating the continuous latent space offered by the PCA-VAE, LDMs could potentially refine their sampling processes and mitigate some limitations associated with discrete latent spaces. This synergy promises a pathway towards enhanced image quality, faster generation speeds, and improved control over the creative output. Specifically, the PCA-VAE’s disentangled representation could serve as a more informative prior for the diffusion process, guiding it towards plausible and high-fidelity samples with reduced computational demands. Further research exploring this intersection could unlock novel methods for manipulating and refining the generative capabilities of LDMs, leading to more efficient and powerful AI systems.
Generative models frequently depend on discrete quantization-a process of approximating continuous data with a finite set of values-which introduces computational burdens and potential information loss. This research demonstrates a pathway towards circumventing these limitations by leveraging a continuous latent space, enabling the creation of more efficient and robust generative systems. By minimizing the need for discrete approximations, the proposed method promises reduced computational costs, faster training times, and the potential for generating higher-fidelity outputs. The implications extend beyond mere efficiency; continuous representations facilitate smoother transitions between generated samples and offer greater control over the generative process, ultimately unlocking new possibilities in fields like image synthesis, data augmentation, and creative content generation.
![PCA-VAE learns interpretable and continuous latent axes, as demonstrated by modifying a single latent coefficient <span class="katex-eq" data-katex-display="false"> [-2, 2] </span> and observing coherent semantic transitions in features like illumination, head pose, and facial structure.](https://arxiv.org/html/2602.18904v1/images/scan_c3_strip.png)
The pursuit of robust generative models, as demonstrated by PCA-VAE, echoes a fundamental principle of enduring systems. The model’s innovative use of a differentiable PCA layer to avoid codebook collapse isn’t merely a technical refinement; it’s a commitment to graceful decay. As Linus Torvalds once stated, “Talk is cheap. Show me the code.” This paper does precisely that – it moves beyond theoretical discussions and presents a concrete implementation addressing the fragility inherent in discrete latent spaces. The architecture, built upon the foundations of PCA and autoencoders, implicitly acknowledges the importance of historical context – a continuous, interpretable latent space is less prone to catastrophic failure than a brittle, quantized one. This is a system designed not just for immediate performance, but for long-term stability.
What Lies Ahead?
The introduction of PCA-VAE represents a local minimum in the ongoing struggle against information entropy. Every bug in its implementation, every limitation encountered in scaling, is a moment of truth in the timeline of generative modeling. The paper successfully addresses the codebook collapse endemic to vector quantization, but this is merely a symptom treated, not the disease cured. The inherent tension between discrete representation and continuous generation will undoubtedly resurface in new forms, demanding further refinement of differentiable approximations.
Future work will likely focus on extending this approach beyond the relatively constrained latent spaces currently explored. The true test of this architecture won’t be reconstruction fidelity-all systems eventually degrade-but its capacity to navigate high-dimensional complexities while preserving meaningful interpretability. The promise of disentangled latent spaces remains largely unrealized; PCA-VAE offers a potentially more graceful aging process, but it does not guarantee immortality.
Ultimately, this research highlights a fundamental truth: technical debt is the past’s mortgage paid by the present. Each simplification, each approximation, accrues interest. The challenge isn’t to eliminate debt-that is impossible-but to manage it responsibly, ensuring that the architecture doesn’t collapse under the weight of its own history. The pursuit of elegant solutions, while admirable, must be tempered with an acceptance of inevitable decay.
Original article: https://arxiv.org/pdf/2602.18904.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- All Skyblazer Armor Locations in Crimson Desert
- Robinhood’s $75M OpenAI Bet: Retail Access or Legal Minefield?
- How to Get the Sunset Reed Armor Set and Hollow Visage Sword in Crimson Desert
- How to Catch All Itzaland Bugs in Infinity Nikki
- Speedsters Sandbox Roblox Codes
- Re:Zero Season 4 Episode 3 Release Date & Where to Watch
- Who Can You Romance In GreedFall 2: The Dying World?
- Top 10 Must-Watch Isekai Anime on Crunchyroll Revealed!
- Black Sun Shield Location In Crimson Desert (Buried Treasure Quest)
- Top 8 UFC 5 Perks Every Fighter Should Use
2026-02-24 17:40