Ising Machines: A New Edge in Error Correction
![Replica-coupled models-specifically independent, penalty-spin, and stacked configurations-explore diverse strategies for harnessing the power of [latex]P=5[/latex] replicas to navigate the inherent chaos within complex systems.](https://arxiv.org/html/2601.09462v1/x1.png)
Researchers have identified a superior architecture for mitigating errors in Ising machines, paving the way for more reliable solutions to complex optimization problems.
Researchers have identified a superior architecture for mitigating errors in Ising machines, paving the way for more reliable solutions to complex optimization problems.
New research reveals fundamental constraints on asymptotic safety as a path toward a complete theory of quantum gravity, challenging its viability at extremely high energies.
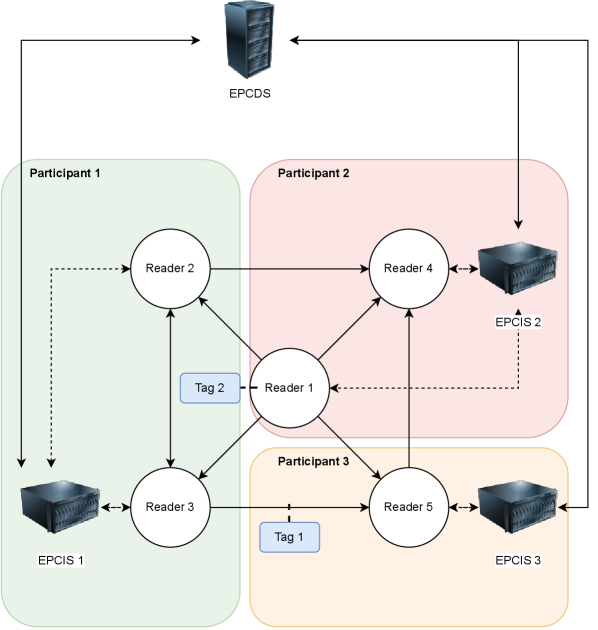
A new analysis reveals critical vulnerabilities in RFID-based traceability systems and proposes a path-based authentication method to enhance security and protect sensitive data.
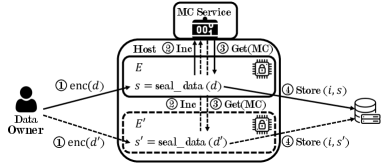
A new analysis reveals that cloning attacks pose a significant risk to applications leveraging Intel’s Software Guard Extensions, potentially compromising data confidentiality and integrity.
A new review explores how cryptography and differential privacy can enable collaborative machine learning without revealing sensitive data.
A new theoretical framework clarifies the boundaries of efficient error correction by quantifying the solution space for spatially-coupled LDPC codes.
![The study parameterizes bottom-strange meson decay form factors-specifically [latex] f_{+}^{s} [/latex] and [latex] f_{0}^{s} [/latex]-and finds results diverge from prior work due to deliberate choices in simulating heavy quark masses, highlighting the sensitivity of theoretical predictions to foundational assumptions.](https://arxiv.org/html/2601.09480v1/x1.png)
A new study leverages lattice QCD calculations to improve the precision of CKM matrix element determination by bridging the gap between inclusive and exclusive decay analyses.

A new protocol, Merged Bitcoin, proposes a shift in how proof-of-work blockchains secure networks by embracing multiple hashing algorithms.
![The parity-check tensor [latex]H_{2-D}[/latex] is defined for [latex]p=3[/latex], utilizing shifts where [latex]\phi(i) = i[/latex], [latex]\psi(j) = j[/latex], and [latex]\eta(k) = k[/latex], thereby establishing a foundational element for error correction within a two-dimensional system.](https://arxiv.org/html/2601.08927v1/stack.png)
Researchers have developed a new family of quantum error-correcting codes designed to significantly improve data storage and transmission by addressing burst errors with enhanced cycle-free structures.

Researchers have developed a method to maintain the safety and performance of powerful AI models even after they’ve been adapted for specific tasks.