Author: Denis Avetisyan
Researchers have developed a new training technique that dramatically reduces the size of large language models without sacrificing accuracy.
RaBiT achieves state-of-the-art 2-bit quantization by addressing training instability and adapting residual paths for improved performance.
Achieving efficient large language model deployment necessitates extreme quantization, yet this often forces a trade-off between model size and performance. The paper ‘RaBiT: Residual-Aware Binarization Training for Accurate and Efficient LLMs’ addresses this challenge by introducing a novel quantization framework that overcomes limitations in residual binarization, specifically the issue of redundant feature learning-termed inter-path adaptation-which degrades error correction. RaBiT achieves state-of-the-art 2-bit compression by algorithmically enforcing a residual hierarchy, deriving each binary path from a shared full-precision weight and prioritizing functional preservation during training. Can this approach unlock even greater efficiencies and wider applicability for low-bit large language models across diverse hardware platforms?
Deconstructing the Limits of Scale: The Pursuit of Minimal Models
Large Language Models (LLMs) have rapidly become cornerstones of artificial intelligence, exhibiting remarkable proficiency in tasks ranging from text generation to complex reasoning. However, this power comes at a cost: their immense size. Current LLMs often contain billions, even trillions, of parameters, necessitating substantial computational resources and memory for both training and deployment. This presents a significant barrier to wider accessibility, particularly for applications intended for mobile devices, embedded systems, or edge computing environments where processing power and memory are limited. The inability to efficiently deploy these models on resource-constrained devices restricts their potential impact, hindering innovation in areas such as personalized healthcare, real-time translation, and ubiquitous virtual assistants. Consequently, a substantial research effort is focused on developing techniques to dramatically reduce model size without sacrificing the capabilities that make LLMs so valuable.
Model quantization represents a pivotal strategy for diminishing the substantial computational demands of large language models. This technique fundamentally reduces the number of bits used to represent a model’s weights and activations, thereby shrinking its overall size and accelerating inference speed. However, the pursuit of extreme compression – particularly reducing precision to levels like 2-bit or even 1-bit – often introduces a critical trade-off: a marked decline in model accuracy. The reduction in numerical precision can lead to information loss, making it difficult for the model to discern subtle patterns in data. Consequently, sophisticated training methodologies, such as quantization-aware training and mixed-precision quantization, are actively being developed to mitigate these accuracy losses and preserve performance even with highly compressed models. These approaches aim to minimize the impact of reduced precision by strategically adjusting the training process to account for the limitations of lower-bit representations.
Pushing the boundaries of large language model compression requires venturing into extreme quantization – representing model weights with as few as two bits – yet maintaining acceptable performance presents a considerable challenge. Conventional training methods struggle with such severe constraints, as the reduced precision amplifies the impact of rounding errors and can lead to catastrophic accuracy loss. Researchers are therefore actively developing novel training methodologies, including techniques like quantization-aware training and mixed-precision quantization, to mitigate these effects. These approaches aim to account for the limitations of low-bit representations during the training process, effectively guiding the model to learn more robust weights that are less susceptible to precision loss and can still perform complex tasks with limited numerical resources. Success in this area will unlock the potential for deploying powerful language models on edge devices and in resource-constrained environments.
The Hidden Costs of Symmetry: Unmasking Inter-path Adaptation
Residual binarization aims to achieve extreme quantization by representing weights and activations with only one bit; however, standard Quantization-Aware Training (QAT) methods often encounter difficulties due to a phenomenon termed Inter-path Adaptation. This issue arises from the parallel nature of residual binary networks, where multiple binary paths can converge on learning the same or highly correlated features. Consequently, the network’s overall representational capacity is not fully utilized, and the potential benefits of the architecture – namely, efficient computation and reduced memory footprint – are undermined as the model fails to maintain accuracy when significantly reducing bit-widths. The effect is a limitation on the achievable compression rate without substantial performance degradation.
Inter-path adaptation in residual binarization manifests as the learning of correlated feature representations across the parallel binary pathways within the network. This occurs because, during training, each path attempts to minimize loss independently, leading to a convergence where multiple paths encode similar information. Consequently, the architectural benefit of having multiple, diverse binary representations is lost, as the redundancy reduces the overall expressiveness of the quantized model and limits its capacity to represent complex functions efficiently at extremely low bit-widths. The phenomenon is particularly pronounced with standard Quantization-Aware Training (QAT) methods which do not explicitly address this redundancy.
Redundancy introduced during residual binarization directly limits the expressive capacity of the resulting quantized model. As parallel binary paths learn to represent similar features, the network’s ability to model complex relationships within the data decreases. This diminished expressiveness manifests as a significant drop in accuracy, particularly when deploying models at extremely low bit-widths-typically below 8 bits-where the capacity to represent information is already constrained. The effect is not simply a reduction in signal strength, but a fundamental inability to differentiate between nuanced inputs due to the overlapping and therefore uninformative feature representations.
RaBiT: Forging Diversity in the Machine
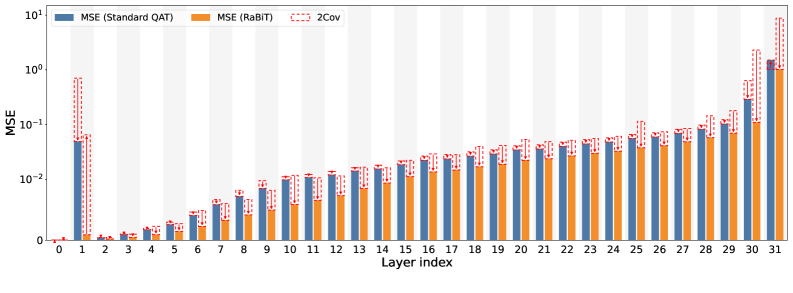
Residual-Aware Binarization Training (RaBiT) differentiates itself from standard Quantization-Aware Training (QAT) by actively promoting diversity among the multiple binary paths created during quantization. Traditional binarization often results in similar or identical binary representations for different weights, limiting the network’s representational capacity. RaBiT addresses this by incorporating a diversity-promoting loss term during training, encouraging each binary path to learn distinct features and contribute uniquely to the overall network function. This explicit encouragement of diversity mitigates performance degradation typically observed in highly quantized networks and improves the model’s robustness and capacity to represent complex functions with limited bit-width.
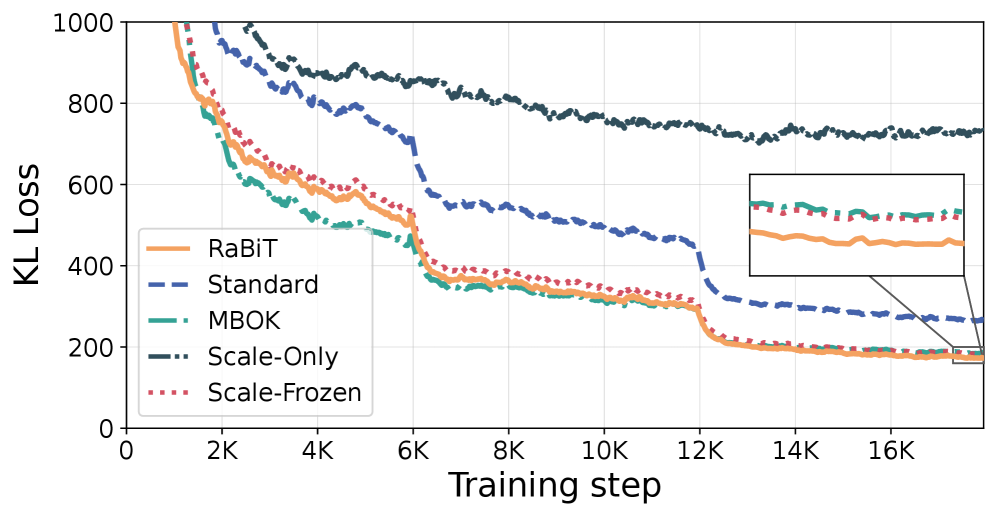
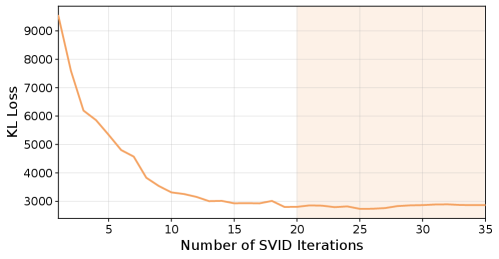
RaBiT’s initialization strategy centers on two key components to improve the initial quantized network performance. Function-Aware Initialization pre-trains binary weights based on the functional importance of each layer, creating a more effective starting point than random initialization. Complementing this, I/O Channel Importance Scaling analyzes the sensitivity of each input/output channel and adjusts the scaling factors accordingly; this process demonstrably reduces initial Kullback-Leibler (KL) Divergence Loss by 81% compared to standard quantization-aware training, leading to faster convergence and improved accuracy during subsequent training phases. This targeted initialization minimizes the distribution shift between full-precision and quantized weights from the outset.
The RaBiT framework addresses limitations of Inter-path Adaptation during quantization by minimizing the Kullback-Leibler (KL) Divergence between the full-precision and quantized weight distributions. This is achieved through the implementation of efficient computational methods, including Binary GEMV (Generalized Matrix Vector Multiplication) and SVID (Stochastic Weight Importance Distribution). Specifically, the incorporation of I/O Channel Importance Scaling demonstrably reduces the initial KL Divergence Loss by 81%, indicating a significantly improved alignment between the full-precision and quantized networks at the start of training and mitigating potential accuracy degradation associated with distribution mismatch.
The Proof of Concept: Unleashing Minimal Models
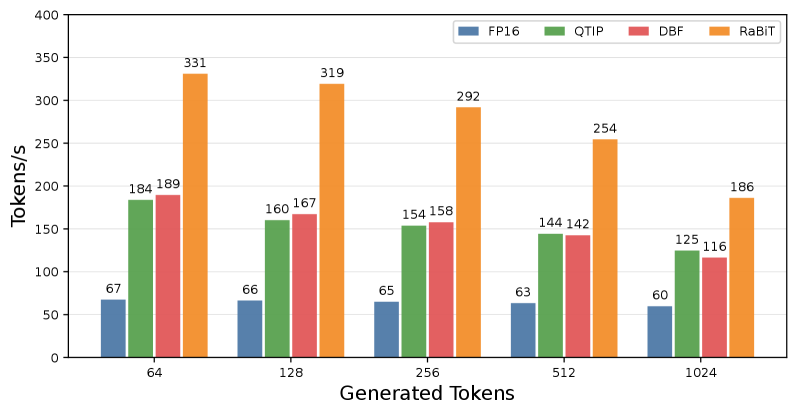
Recent experimentation reveals that RaBiT – a novel training technique – markedly surpasses conventional Quantization Aware Training (QAT) when applied to the challenging task of training Large Language Models (LLMs) with just 2-bit quantization. This performance difference isn’t merely incremental; RaBiT consistently achieves superior results, indicating a fundamental improvement in how LLMs can be compressed without substantial accuracy loss. By optimizing the training process to better accommodate the constraints of extreme quantization, RaBiT allows for significantly smaller model sizes and faster inference speeds, paving the way for deployment on resource-constrained devices without sacrificing the quality of generated text or the model’s reasoning capabilities. This advantage is particularly crucial as the demand for accessible and efficient AI continues to grow.
Recent advancements in low-bit quantization techniques have yielded remarkable results, and the RaBiT method demonstrates a significant leap forward in achieving both accuracy and speed. Across a diverse range of benchmark tasks, RaBiT consistently outperforms traditional quantization approaches, notably delivering up to a 4.49x increase in inference speed. This improvement isn’t achieved at the expense of performance; RaBiT maintains competitive accuracy levels when compared to more complex, hardware-intensive vector quantization methods. This balance between efficiency and effectiveness positions RaBiT as a promising solution for deploying large language models in resource-constrained environments, offering a pathway to faster and more accessible artificial intelligence.
Evaluations using the Llama2-7B language model on the WikiText-2 benchmark reveal RaBiT’s superior performance; the model achieves a perplexity of 5.78, demonstrably lower than both QTIP at 5.86 and MBOK at 6.99. This improvement in language modeling ability extends to reasoning tasks, where RaBiT attains 61.51% average zero-shot accuracy – a significant advancement over QTIP’s 58.97%. These results highlight RaBiT’s capacity to not only generate coherent text but also to effectively perform complex reasoning without task-specific training, suggesting a substantial leap forward in the efficiency and capability of quantized large language models.
Beyond the Horizon: Towards a Universal Framework for Efficient AI
Researchers are now directing efforts toward generalizing the principles behind RaBiT – a method that enhances model robustness through bit-wise diversity – to even more aggressive quantization schemes, specifically 4-bit quantization. This pursuit acknowledges that while lower bit-widths offer substantial compression, they often exacerbate performance degradation; RaBiT’s approach to strategically introducing diversity across the bits promises to mitigate these losses. By adapting the core tenets of RaBiT to 4-bit representations, the team anticipates unlocking significant efficiency gains without sacrificing model accuracy, potentially enabling the deployment of sophisticated deep learning models on resource-limited edge devices with even greater feasibility.
The synergistic potential of combining RaBiT with established model compression methodologies presents a promising avenue for maximizing efficiency. Research indicates that techniques like pruning – which removes redundant connections – and knowledge distillation – transferring learning from a larger model to a smaller one – often complement quantization strategies. By integrating RaBiT’s diversity-promoting quantization with either pruning or knowledge distillation, or even a combination of both, models could potentially achieve significantly smaller sizes and faster inference speeds without substantial accuracy loss. This combined approach addresses different facets of model complexity – reducing parameter count, simplifying network structure, and optimizing numerical precision – leading to a holistic reduction in computational demands and memory footprint, ultimately broadening the scope of deployable deep learning applications.
The long-term vision centers on establishing a unified and adaptable deep learning framework, designed to overcome current limitations in computational demand and accessibility. This framework aims to transcend hardware constraints, enabling the seamless deployment of artificial intelligence across a truly universal range of devices – from powerful servers to resource-limited edge devices and mobile platforms. By prioritizing efficiency without sacrificing accuracy, the initiative seeks to democratize AI, fostering innovation and application in previously inaccessible contexts and ultimately bringing the benefits of advanced machine learning to every corner of the digital world.
The pursuit of low-bit precision, as demonstrated by RaBiT, isn’t simply about shrinking models; it’s a calculated disruption of established norms. This framework doesn’t accept the limitations of quantization as a fixed constraint, but actively seeks to correct errors and adapt inter-path dependencies. Ada Lovelace observed, “The Analytical Engine has no pretensions whatever to originate anything. It can do whatever we know how to order it to perform.” RaBiT embodies this principle-it doesn’t invent intelligence, but meticulously refines the process of compression, forcing existing architectures to perform beyond initial expectations. By stabilizing training and achieving state-of-the-art results, the work demonstrates a systematic reverse-engineering of the constraints inherent in large language models.
What’s Next?
The assertion that RaBiT achieves state-of-the-art 2-bit compression isn’t the point; it’s the confession. The system yields, but only under duress. This work elegantly demonstrates a path to reducing LLM bit-width, but the resulting fragility hints at a deeper truth: current architectures are fundamentally unprepared for such extreme pruning. The coupled training and function-aware initialization are not solutions, but elaborate bandages covering foundational weaknesses. The question isn’t whether further gains are possible, but what must be broken to achieve them.
Future efforts shouldn’t focus solely on mitigating the symptoms of quantization. Instead, the field must confront the inherent limitations of the underlying representational scheme. Exploration of alternative numerical formats, beyond the constraints of binary precision, is critical. A bug, in this case, is the system confessing its design sins – the architecture’s inability to gracefully handle such radical simplification. True progress demands a willingness to reverse-engineer the very foundations of these models.
Ultimately, the goal isn’t just to compress LLMs; it’s to understand why they resist compression. The pursuit of lower bit-widths serves as a stress test, revealing the fault lines in our understanding of intelligence itself. The next iteration won’t be about incremental improvements; it will be about embracing controlled demolition, dismantling what exists to build something genuinely resilient.
Original article: https://arxiv.org/pdf/2602.05367.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- All Skyblazer Armor Locations in Crimson Desert
- How to Get the Sunset Reed Armor Set and Hollow Visage Sword in Crimson Desert
- One Piece Chapter 1180 Release Date And Where To Read
- All Shadow Armor Locations in Crimson Desert
- Marni Laser Helm Location & Upgrade in Crimson Desert
- All Golden Greed Armor Locations in Crimson Desert
- All Helfryn Armor Locations in Crimson Desert
- How to Beat Stonewalker Antiquum at the Gate of Truth in Crimson Desert
- All Icewing Armor Locations in Crimson Desert
- Black Sun Shield Location In Crimson Desert (Buried Treasure Quest)
2026-02-07 19:57