Author: Denis Avetisyan
New research delivers a complete framework for verifying that machine learning models are truly protected against malicious data manipulation during training.
This work presents a mixed-integer programming approach for the exact certification of robustness against data-poisoning attacks, providing sound and complete guarantees on training dynamics.
Despite growing concerns about the security of machine learning systems, formally verifying robustness against adversarial data manipulation remains a significant challenge. This paper introduces ‘Exact Certification of Data-Poisoning Attacks Using Mixed-Integer Programming’, a novel framework that provides sound and complete guarantees for certifying robustness during neural network training. By formulating data poisoning, training dynamics, and evaluation within a single mixed-integer quadratic programming (MIQCP) problem, we can provably identify worst-case attacks and bound the effectiveness of all possible poisoning strategies. Does this approach represent a viable path toward building truly trustworthy and reliable machine learning systems in adversarial environments?
The Insidious Threat of Data Poisoning
Modern machine learning, while demonstrating remarkable capabilities, faces a growing threat from data poisoning attacks. These attacks involve the deliberate introduction of flawed or malicious data into the training dataset, subtly corrupting the learning process. Unlike traditional security breaches targeting model deployment, data poisoning strikes at the foundation of the system – the data itself. A successful attack doesn’t necessarily aim to immediately break the model; instead, it seeks to induce specific, predictable errors in its predictions, potentially leading to significant consequences in applications like fraud detection, autonomous driving, and medical diagnosis. The increasing reliance on large, often publicly sourced, datasets further exacerbates this vulnerability, as verifying the integrity of every data point becomes increasingly impractical. Consequently, machine learning systems are susceptible to insidious manipulation, demanding innovative defense mechanisms focused on data validation and robust learning algorithms.
Data poisoning attacks represent a significant and evolving threat to the reliability of machine learning systems. These attacks don’t necessarily require gaining direct access to the model itself; instead, malicious actors focus on corrupting the training data used to build it. The spectrum of these manipulations is broad, ranging from subtle perturbations – minor alterations to existing data points that are difficult to detect – to the outright fabrication of entirely new, malicious data. Consequently, even a small percentage of poisoned data can drastically reduce a model’s accuracy, introduce biased predictions, or even cause complete functional failure. This compromise of integrity isn’t limited to specific applications; any system reliant on machine learning – from spam filters and fraud detection to medical diagnosis and autonomous vehicles – is potentially vulnerable, highlighting the critical need for robust defense mechanisms.
Distinguishing between bounded and unbounded perturbations in data poisoning attacks is paramount for effective defense strategies. Bounded perturbations involve subtle alterations to existing data points, remaining within plausible ranges and often mimicking natural data variations – making detection incredibly difficult. Conversely, unbounded perturbations introduce drastic, often unrealistic changes or entirely fabricated data, which, while easier to identify, can still significantly degrade model performance if left unchecked. The effectiveness of defense mechanisms – such as robust statistics, anomaly detection, or data sanitization techniques – is directly tied to their ability to differentiate and mitigate these varying degrees of manipulation. Consequently, a nuanced understanding of perturbation types enables the development of targeted defenses, moving beyond generic solutions and bolstering the resilience of machine learning systems against increasingly sophisticated adversarial threats.
Formalizing Resilience with Mixed-Integer Programming
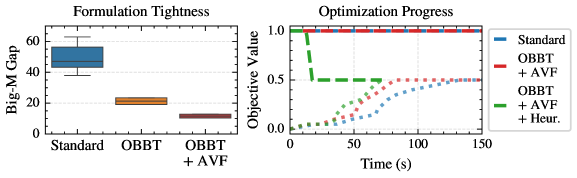
Current adversarial defense strategies frequently rely on empirical evaluation, offering limited assurance regarding actual robustness against adaptive attacks. This work introduces a methodology utilizing mixed-integer programming (MIP) to directly incorporate robustness constraints during the model training process. By formulating the training problem as a MIP, we move beyond heuristic defenses and establish formal, verifiable guarantees on the model’s resilience. This approach allows for the explicit enforcement of robustness criteria, ensuring that the resulting model is demonstrably resistant to perturbations within a specified threat model, and provides a means to certify robustness against all possible attacks within that model.
The Big-M formulation allows for the representation of the Rectified Linear Unit (ReLU) activation function, max(0, x) , as a set of mixed-integer linear constraints. Specifically, a binary variable, δ, is introduced to indicate whether the input ‘x’ to the ReLU is positive. The formulation then utilizes a large constant, ‘M’, to define constraints that ensure y = x \cdot \delta accurately represents the ReLU output. If ‘x’ is positive, δ is set to 1 and y = x ; if ‘x’ is negative, δ is 0 and y = 0 . This precise logical encoding enables the formal verification of network behavior and facilitates a rigorous assessment of model vulnerability to adversarial inputs by allowing optimization-based analysis of the network’s decision boundaries.
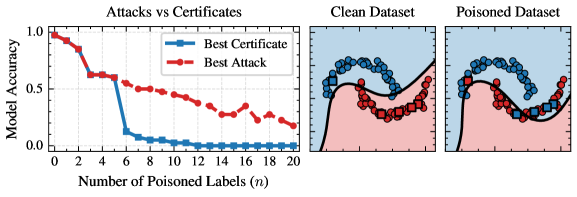
The presented framework delivers provable robustness guarantees, meaning any attack that violates the certified robustness bound is demonstrably suboptimal given the threat model. This is achieved through a formulation that allows for the computation of optimal adversarial attacks, and consequently, the derivation of certificates bounding the maximum possible perturbation an input can withstand without altering the model’s prediction. Evaluation on benchmark datasets, including those commonly used for adversarial robustness assessment, confirms the framework’s ability to generate these optimal attacks and provide correspondingly tight robustness certificates, validating its soundness and completeness under the specified threat models.
Tracing the Impact of Attacks on Training Dynamics
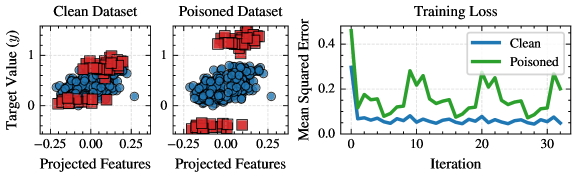
The proposed method facilitates the observation of model parameter changes throughout the training process, even when training data includes instances modified by adversarial attacks. This tracking capability enables the identification of how specific attack strategies influence parameter updates; for example, it can reveal whether an attack causes parameters to converge towards suboptimal values or introduces instability during training. By monitoring these parameter trajectories, the impact of various poisoning techniques – such as data manipulation to bias the model or disrupt convergence – can be quantified and analyzed, offering insights into the vulnerabilities of machine learning models and informing the development of more robust training procedures.
Parameter updates during training are computed using Batch Gradient Descent, where the gradient is calculated across a batch of training examples. Our framework enables observation of these updates at each iteration, allowing for the identification of how individual, maliciously crafted data points influence the overall gradient and subsequent parameter adjustments. Specifically, we track the contribution of each data point to the gradient vector, quantifying the extent to which poisoned samples can skew the training process. This granular analysis reveals whether attacks manifest as consistent perturbations or sporadic, large-magnitude shifts in parameter updates, providing insights into attack strategy effectiveness and potential detection mechanisms.
Empirical results on the Halfmoons dataset demonstrate attack optimality for scenarios where the number of malicious data points, n, is less than 6. Beyond this threshold, while optimality isn’t always provable, the framework provides formal certificates quantifying the attack’s performance. Furthermore, the implementation of the Optimized Backtracking Branch-and-Tighten (OBBT) algorithm demonstrably reduces the magnitude of Big-M constants used in the formal verification process; measured reductions in the gap between initial and final constant values serve as quantitative evidence of this tightening, improving the efficiency and scalability of the certification process.
Bridging the Gap: From Training to Real-World Resilience
Although this research prioritizes strengthening machine learning models during the training phase, it is essential to recognize that training-time robustness and resilience at deployment are intrinsically linked. A model fortified against adversarial perturbations during training isn’t automatically invulnerable to all potential attacks encountered during inference. Subtle shifts in data distribution, novel attack strategies not considered during training, or even the nuances of real-world sensor noise can compromise a seemingly robust system. Consequently, a truly secure machine learning pipeline demands coordinated efforts across both training and inference stages, acknowledging that vulnerabilities can emerge at any point in the process and require continuous monitoring and adaptation to maintain reliable performance.
Research indicates a critical disconnect between bolstering a model’s defenses during training and ensuring its secure operation upon deployment. While techniques to enhance robustness against adversarial examples during the training phase demonstrably improve performance under certain attack scenarios, this work reveals that maximizing training-time resilience does not inherently translate to comprehensive protection during inference. Specifically, a model rigorously hardened against one class of attacks may remain vulnerable to subtly different, yet equally malicious, perturbations encountered in a real-world deployment setting. This suggests that a singular focus on training-time robustness is insufficient; instead, a more nuanced approach is required to address the evolving landscape of potential inference-time threats and guarantee genuinely secure machine learning systems.
Effective machine learning security necessitates a comprehensive strategy extending beyond simply fortifying the training process. Current practices often prioritize robustness during training, aiming to build models resilient to adversarial manipulation of training data; however, this approach doesn’t automatically translate to unwavering security during deployment. A truly secure system requires simultaneous attention to inference-time vulnerabilities-attacks that exploit the model after it has been trained and is actively making predictions. This holistic view acknowledges that even a model rigorously trained against certain perturbations can remain susceptible to novel or cleverly crafted attacks during its operational phase. Therefore, developers must proactively assess and mitigate risks at both stages-training and deployment-to create machine learning systems demonstrably resistant to a wide spectrum of potential threats and ensure sustained, reliable performance in real-world applications.
The pursuit of robustness certification, as detailed in this work, benefits from a relentless focus on essential elements. This paper’s complete mixed-integer programming framework achieves precisely that – a reduction of the problem to its core components to provide sound and complete guarantees. As Linus Torvalds once stated, “Talk is cheap. Show me the code.” This sentiment perfectly encapsulates the approach taken here; abstract theory is solidified into a concrete, verifiable system. The framework doesn’t merely claim robustness against data poisoning attacks, it demonstrates it through rigorous, formal verification, embodying the principle that simplicity – in this case, a focused, complete model – is the ultimate intelligence.
Further Steps
The presented framework achieves a demonstrable completeness. This is not, however, a destination. Current scalability remains the primary constraint. Certification, even for modestly sized models and datasets, demands computational resources that preclude broad application. Future work must address this directly-not through approximation, but through fundamental advances in solver technology and algorithmic design. Clarity is the minimum viable kindness, and imprecise results offer little solace.
A crucial, largely unexplored area concerns the interplay between data poisoning and the inherent complexities of training dynamics. This work assumes a static training process. Yet, models rarely converge predictably. Certification methods must account for stochasticity, regularization, and the cascading effects of individual data point influence. A complete theory necessitates an understanding not merely of what a poisoned dataset does, but how it alters the learning process itself.
Ultimately, the pursuit of robustness is a Sisyphean task. Attack surfaces evolve. Defenses become targets. The value of formal verification lies not in achieving absolute security-an illusion-but in precisely quantifying the boundaries of vulnerability. Further refinement, then, demands a shift in focus: from proving absence of poisoning, to rigorously characterizing the cost of successful attacks.
Original article: https://arxiv.org/pdf/2602.16944.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- All Skyblazer Armor Locations in Crimson Desert
- How to Get the Sunset Reed Armor Set and Hollow Visage Sword in Crimson Desert
- Robinhood’s $75M OpenAI Bet: Retail Access or Legal Minefield?
- How to Catch All Itzaland Bugs in Infinity Nikki
- Speedsters Sandbox Roblox Codes
- Invincible: 10 Strongest Viltrumites in Season 4, Ranked
- Jojo’s Bizarre Adventure Ties Frieren As MyAnimeList’s New #1 Anime
- Re:Zero Season 4 Episode 3 Release Date & Where to Watch
- Top 10 Must-Watch Isekai Anime on Crunchyroll Revealed!
- Who Can You Romance In GreedFall 2: The Dying World?
2026-02-23 06:11