Author: Denis Avetisyan
A new approach minimizes artifacts introduced during lossy compression of scientific datasets, ensuring data quality remains high even with significant size reduction.
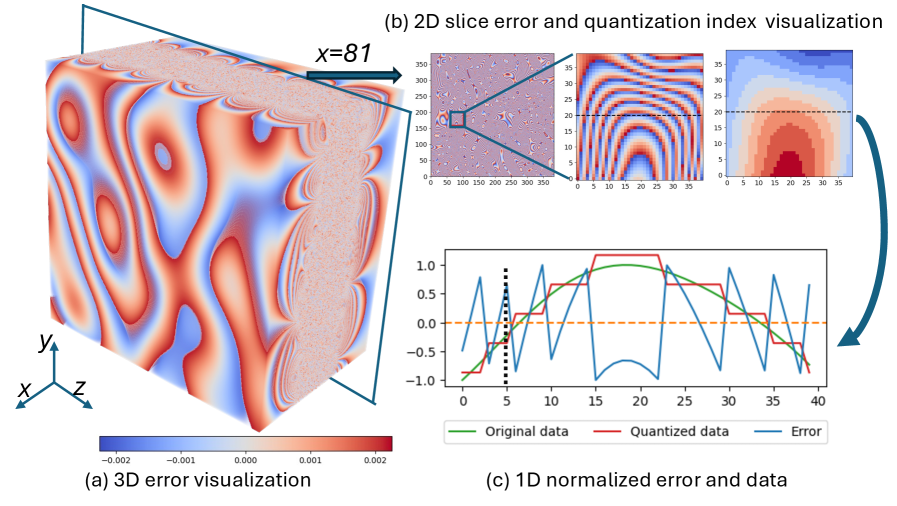
Quantization-aware interpolation and parallel computing techniques mitigate artifacts in pre-quantization based scientific data compressors, enabling error-bounded compression.
The increasing volume of scientific data necessitates lossy compression techniques, yet these often introduce artifacts that degrade data quality. This paper, ‘Mitigating Artifacts in Pre-quantization Based Scientific Data Compressors with Quantization-aware Interpolation’, addresses this challenge by investigating and reducing artifacts inherent in pre-quantization based compression schemes. We present a novel quantization-aware interpolation algorithm, efficiently parallelized for both shared and distributed-memory systems, that demonstrably improves decompressed data quality without compromising compression throughput. Can this approach unlock new possibilities for balancing compression efficiency and scientific accuracy in large-scale data analysis?
The Cost of Convenience: Limits of Traditional Compression
Lossy compression techniques are foundational to modern digital life, enabling the efficient storage and transmission of images, audio, and video; however, this convenience comes at a cost. The very principle of lossy compression – discarding data deemed perceptually unimportant – inevitably introduces artifacts and distortions. While often imperceptible at moderate compression levels, aggressively reducing file size amplifies these imperfections, manifesting as blockiness in images, muddiness in audio, or blurring in video. The trade-off between file size and fidelity is a constant challenge, as pushing for higher compression ratios demands increasingly sophisticated algorithms to minimize noticeable degradation, but a point is always reached where the loss of information becomes unacceptable, limiting the effectiveness of these methods for critical data applications.
As datasets balloon in size – driven by advancements in fields like genomics, medical imaging, and astrophysics – conventional lossy compression techniques face escalating challenges in maintaining data fidelity. These methods, designed to discard less perceptually significant information, often struggle to achieve high compression ratios without introducing noticeable artifacts or distortions, particularly when applied to massive datasets. The core issue lies in the scaling of error; while a small amount of data loss might be imperceptible in a smaller file, it becomes amplified and increasingly problematic as the dataset grows. Consequently, traditional approaches frequently necessitate a trade-off between compression performance and acceptable levels of data degradation, hindering their effectiveness in applications demanding both efficiency and accuracy. This limitation motivates the development of novel compression strategies capable of intelligently managing data loss and preserving critical information even at extremely high compression ratios.
Current lossy compression algorithms frequently operate as ‘black boxes’, offering limited insight into the nature or extent of data alteration during the compression process. This lack of transparency presents a significant challenge, as users often have no way to predict where or how information will be lost, making these methods unsuitable for applications demanding data integrity, such as medical imaging or scientific research. The inherent unpredictability stems from the algorithms’ reliance on discarding data deemed perceptually irrelevant, a subjective assessment that doesn’t translate into quantifiable error bounds. Consequently, seemingly minor compression can introduce subtle, yet critical, distortions, and the inability to guarantee a maximum level of data loss raises concerns about the reliability and reproducibility of results derived from compressed data.
The demand for data compression continues to escalate alongside the exponential growth of digital information, yet conventional lossy methods frequently fall short by prioritizing size reduction at the expense of data integrity. Consequently, research is increasingly focused on developing compression techniques that move beyond simple ratio optimization to offer guaranteed levels of controlled degradation. These advanced approaches aim to establish explicit error bounds, ensuring that data reconstruction remains within acceptable tolerances even at high compression rates. This shift signifies a move toward predictable data loss, allowing users to balance storage efficiency with the preservation of critical information, and opening new possibilities for applications where even minor distortions are unacceptable, such as medical imaging or scientific simulations.
Parallel Pathways: Pre-quantization for Efficiency
Pre-quantization improves compression parallelism by altering the data’s structure to minimize sequential dependencies. Traditional compression methods often require processing data elements in a specific order due to inherent relationships between them. Applying a linear-scaling quantization step before encoding decouples these dependencies, allowing independent processing of data blocks. This enables compressors to distribute the workload across multiple processing units – such as GPU cores – concurrently, rather than being limited by serial processing requirements. The reduction in sequential constraints directly translates to increased throughput and reduced compression times, particularly for large datasets.
Linear-scaling quantization, when applied as a pre-processing step to compression, improves processing speed by reducing the dynamic range of input data. This technique scales data values linearly before encoding, effectively decreasing the number of bits required to represent each value and lowering computational complexity during the encoding process. By pre-quantizing, compressors minimize operations on high-precision data, allowing for faster execution, particularly when leveraging the parallel processing capabilities of GPUs. This approach facilitates significant throughput increases by streamlining data handling and reducing the potential for performance bottlenecks associated with large dynamic ranges.
Pre-quantization streamlines data preparation for GPU-based compression by transforming the input data into a format more readily processed in parallel. GPUs excel at performing the same operation on multiple data points simultaneously, but traditional compression algorithms often involve sequential dependencies that limit this capability. By scaling and quantizing the data before encoding, pre-quantization reduces these dependencies, enabling greater utilization of GPU resources. This results in maximized throughput – the amount of data processed per unit of time – and minimized bottlenecks that can occur when the GPU is waiting for data from the CPU or memory. The increased parallelism directly translates into faster compression and decompression speeds, particularly for large datasets.
Modern data compression algorithms are increasingly leveraging pre-quantization techniques, as demonstrated by implementations in compressors such as cuSZ, FZ-GPU, and cuSZp. These algorithms integrate linear-scaling quantization as a preprocessing step prior to encoding, enabling greater parallelism and improved performance on GPU architectures. Specifically, cuSZ and cuSZp utilize pre-quantization to accelerate entropy coding, while FZ-GPU employs it to enhance the efficiency of its pattern matching and transformation stages. The successful integration of pre-quantization into these diverse compression schemes highlights its versatility and effectiveness as a method for boosting throughput and reducing computational bottlenecks.
Restoring Fidelity: Artifact Mitigation Strategies
Lossy compression techniques, while effective at reducing storage space and transmission bandwidth, inherently introduce artifacts due to the discarding of data during the compression process. These artifacts manifest as visible distortions, such as blocking, ringing, and blurring, and are a direct consequence of the quantization step, where continuous data is mapped to a finite set of discrete values. Despite ongoing advancements in compression algorithms and increased computational power, the fundamental trade-off between compression ratio and data fidelity ensures that artifacts will persist, particularly at high compression rates. The nature and severity of these artifacts are dependent on the specific compression algorithm employed, the characteristics of the original data, and the quantization parameters used; however, complete elimination of artifacts in lossy compression is not generally achievable without reverting to lossless methods.
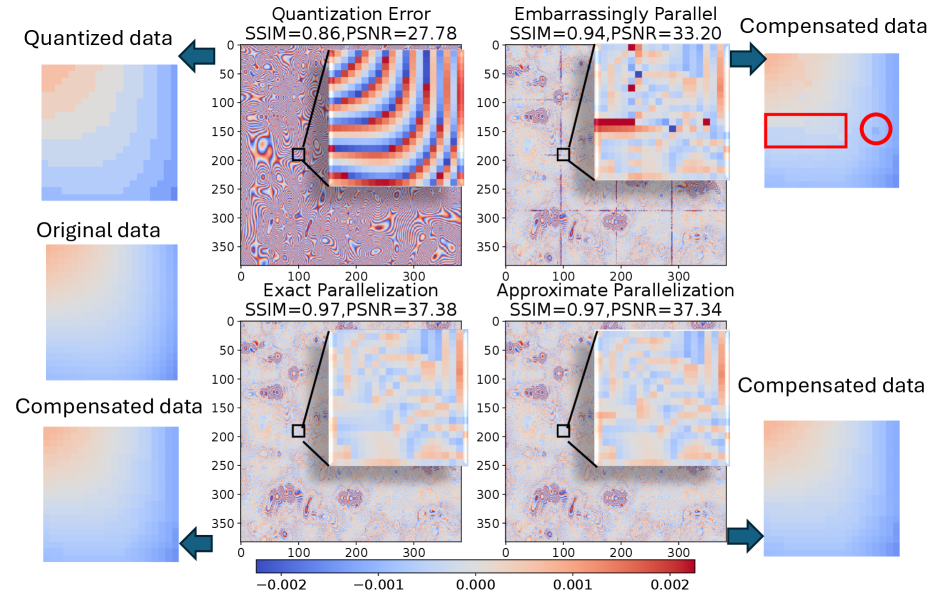
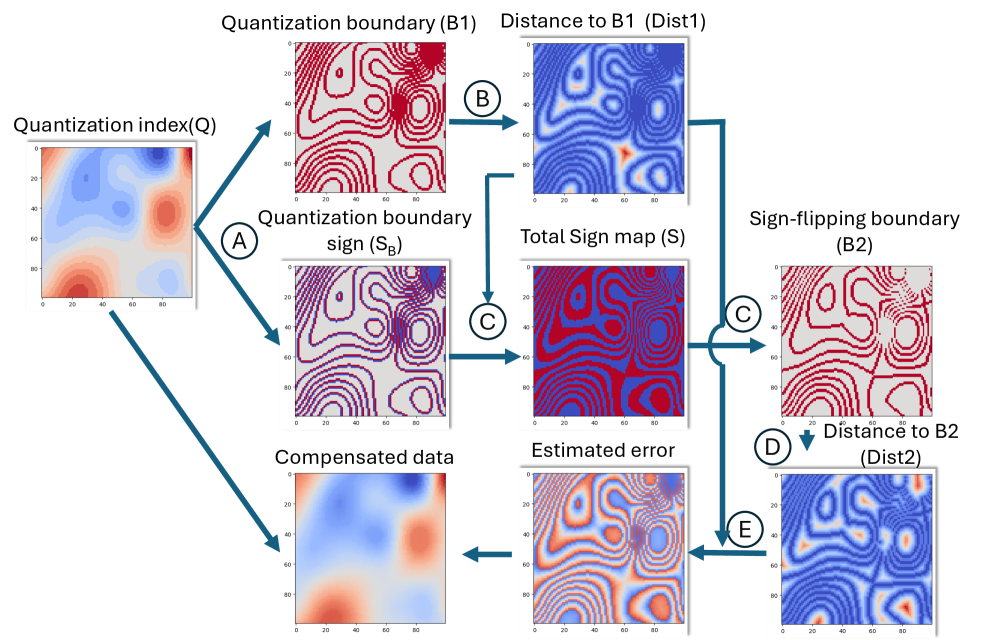
Filtering techniques, including Gaussian, Uniform, and Wiener filters, are foundational artifact mitigation strategies in lossy compression by smoothing residual quantization errors. These filters operate by convolving a kernel with the decompressed data, reducing high-frequency distortions introduced during the quantization process. Distance transforms, specifically the Euclidean distance transform, identify and minimize artifacts by calculating the distance to the nearest non-artifact pixel. This approach is particularly effective in reconstructing damaged or missing data points. The selection of an optimal filter or distance transform depends on the specific characteristics of the compression scheme and the nature of the artifacts present in the decompressed data; combinations of these techniques are often employed to achieve superior results.
Benchmarking of the quantization-aware interpolation method against standard decompression techniques indicates a substantial improvement in perceptual quality, quantified by the Structural Similarity Index Measure (SSIM). Specifically, tests performed on scientific datasets demonstrate an SSIM improvement of up to 108.33% following artifact mitigation. This metric indicates a significant reduction in distortions introduced by lossy compression, suggesting a closer resemblance between the decompressed data and the original, uncompressed data. The observed improvement confirms the method’s efficacy in preserving data integrity and enhancing the usability of scientific datasets after decompression.
Effective artifact mitigation in lossy compression depends on characterizing quantization errors. The quantization process introduces discrepancies between the original data and its compressed representation, and these errors possess both magnitude and sign. The Quantization Index (QI) represents the level of discretization applied during quantization, while the Sign Map indicates the direction of the error-whether the quantized value is higher or lower than the original. Analyzing both the QI and Sign Map allows for targeted artifact reduction techniques; for example, understanding the distribution of error signs enables the application of correction factors, and the QI informs the precision needed for interpolation or filtering. Accurate reconstruction of data relies on modeling these error characteristics inherent in the quantization process.
Parallelization of artifact mitigation techniques is achieved through the utilization of OpenMP for shared-memory parallelism and MPI for distributed-memory parallelism. OpenMP enables thread-level concurrency on multi-core processors, accelerating processing of individual data blocks, while MPI facilitates the distribution of data and computational workload across multiple nodes in a cluster environment. This combined approach allows for significant performance gains and improved scalability with increasing dataset size and computational demands. Specifically, OpenMP handles intra-node parallelism, while MPI manages inter-node communication and workload distribution, allowing for efficient processing of large-scale scientific datasets and minimizing overall processing time.
Beyond Reduction: Optimized Implementations and Future Horizons
Modern image compression strategies, exemplified by compressors like cuSZp2, are increasingly reliant on a synergistic combination of techniques to maximize efficiency. These systems move beyond simple data reduction by first employing pre-quantization, a process that reduces the precision of data before encoding, minimizing the information needing complex processing. This is then coupled with optimized memory access patterns – crucial for leveraging the parallel processing capabilities of GPUs – and advanced prediction methods, such as Lorenzo Prediction. Lorenzo Prediction intelligently anticipates data values, allowing for more effective encoding of the remaining residual information. The resulting architecture isn’t merely about shrinking file sizes; it’s about intelligently preparing and processing data to extract the most compression from available resources, ultimately leading to substantial gains in both compression ratios and processing speed.
Significant gains in compression efficiency have been demonstrated through a novel approach that yields a 1.17x improvement for the cuSZ algorithm and a 1.34x improvement for cuSZp2, all while maintaining consistent structural similarity (SSIM) levels. These results indicate that the proposed method not only reduces file sizes but does so without perceptible degradation in image or video quality, a crucial factor for practical applications. This enhancement in compression ratio translates directly into reduced storage requirements and faster data transmission speeds, offering substantial benefits for industries dealing with large-scale visual data, such as medical imaging, scientific visualization, and high-resolution video streaming.
Modern compression systems increasingly rely on the parallel processing capabilities of Graphics Processing Units (GPUs) to meet the demands of ever-growing datasets and real-time applications. The inherent architecture of GPUs, designed for handling massive amounts of data concurrently, provides a substantial advantage over traditional CPU-based compression methods. This shift enables significantly higher throughput, allowing for faster compression and decompression speeds, and crucially, facilitates scalability to handle larger and more complex data. By offloading computationally intensive compression tasks to the GPU, systems can achieve performance levels previously unattainable, making GPU-based implementations central to the functionality of modern image and video processing pipelines, scientific data archiving, and high-performance computing environments.
The research demonstrates a notable capacity for scalability through parallel processing. Utilizing approximate parallelization with 256 ranks, the method attains an impressive 85.0% efficiency when benchmarked against a base case employing only 64 ranks. This result signifies that, even with an increased number of processing units, the system maintains a high proportion of its ideal performance, indicating a robust ability to leverage additional hardware resources. Such strong scaling performance is crucial for handling increasingly large datasets and achieving real-time compression speeds, particularly within demanding applications like scientific visualization and high-resolution video processing.
Current compression techniques often employ static quantization parameters, potentially sacrificing efficiency when applied to diverse datasets. Future investigations are directed toward developing adaptive quantization schemes capable of dynamically adjusting these parameters based on inherent data characteristics. This approach promises to tailor the compression process to the specific content being encoded, maximizing compression ratios without compromising perceptual quality. By analyzing features within the data – such as local entropy, texture complexity, or color distributions – the system can intelligently select optimal quantization levels for each region, leading to significant gains in both compression efficiency and visual fidelity. Such adaptive strategies represent a crucial step toward intelligent compression systems that respond intelligently to the data they process.
The pursuit of more efficient data compression remains a central challenge in computer science, fueled by the ever-increasing volume of digital information. This demand is simultaneously driving innovation in algorithmic design and hardware capabilities. Future advancements will likely arise not from singular breakthroughs, but from synergistic optimization – refining compression algorithms to exploit the unique strengths of emerging hardware architectures, such as specialized accelerators and heterogeneous computing platforms. This iterative process will necessitate a holistic approach, considering data characteristics, computational resources, and energy efficiency, ultimately pushing the boundaries of what is achievable in lossless and lossy compression techniques and enabling new possibilities in data storage, transmission, and analysis.
The pursuit of efficient data compression, as detailed in the presented work, necessitates a careful balance between minimizing information loss and maximizing compression ratios. This mirrors a fundamental principle in mathematical reasoning: elegance through reduction. As David Hilbert stated, “We must be able to say in a few words what otherwise would require pages.” The algorithm detailed effectively addresses the challenge of artifact mitigation in pre-quantization techniques by employing quantization-aware interpolation-a refinement that distills essential data while discarding superfluous noise. This distillation process, prioritizing clarity and minimizing redundancy, embodies the core concept of achieving maximal information density with minimal representation – a demonstration of intellectual economy. The parallel computing aspect further amplifies this efficiency, allowing for swift and decisive data refinement.
Further Refinements
The presented methodology addresses a predictable failing of lossy compression: the introduction of artifacts. It is, however, a localized correction. The true challenge lies not in polishing the outputs of imperfect algorithms, but in constructing algorithms inherently resistant to such failings. Future work should investigate the potential for integrating quantization-aware interpolation directly into the compression process itself – a preemptive strike, if one will – rather than a reactive measure. The current approach, while effective, remains fundamentally corrective, and correction implies prior imperfection.
Moreover, the parallelization strategies employed, while demonstrably beneficial, are constrained by the underlying architecture. The pursuit of genuinely scalable compression requires a reassessment of data dependencies and a move towards algorithms that naturally lend themselves to distributed processing. The computational cost of artifact mitigation, even with parallelization, represents an ongoing overhead. Eliminating that overhead is not merely an optimization, but a philosophical imperative.
Finally, the assessment of ‘acceptable’ artifact levels remains subjective, tied to the specifics of the scientific domain. A rigorous, domain-agnostic metric for quantifying compression fidelity – one that moves beyond simple error bounds – would be a valuable contribution. Emotion, after all, is a side effect of structure. And clarity is compassion for cognition.
Original article: https://arxiv.org/pdf/2602.20097.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- All Skyblazer Armor Locations in Crimson Desert
- Robinhood’s $75M OpenAI Bet: Retail Access or Legal Minefield?
- How to Get the Sunset Reed Armor Set and Hollow Visage Sword in Crimson Desert
- How to Catch All Itzaland Bugs in Infinity Nikki
- Speedsters Sandbox Roblox Codes
- Invincible: 10 Strongest Viltrumites in Season 4, Ranked
- Jojo’s Bizarre Adventure Ties Frieren As MyAnimeList’s New #1 Anime
- Re:Zero Season 4 Episode 3 Release Date & Where to Watch
- Top 10 Must-Watch Isekai Anime on Crunchyroll Revealed!
- Who Can You Romance In GreedFall 2: The Dying World?
2026-02-25 02:04