Author: Denis Avetisyan
A new framework efficiently unlocks secure searches over sensitive geo-textual data, balancing privacy with performance.
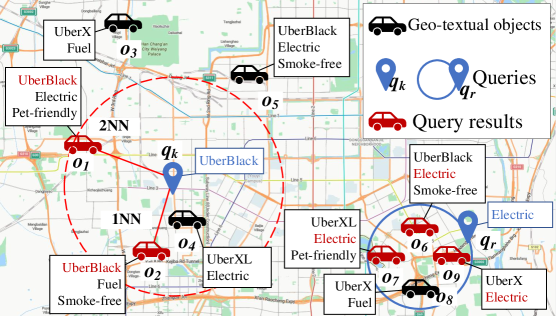
RISK unifies range and k-nearest neighbor queries with a secure hybrid index, achieving significant gains in scalability and leveraging symmetric encryption with IND-CKA2 security for cloud-based data privacy.
Existing solutions for privacy-preserving geo-textual queries typically rely on specialized indices, creating significant overhead when supporting diverse query types. This paper introduces ‘RISK: Efficiently processing rich spatial-keyword queries on encrypted geo-textual data’, a novel framework that unifies range and k-nearest neighbor queries through a secure hybrid index based on a k-nearest neighbor quadtree. RISK achieves provable security under the IND-CKA2 model while demonstrably outperforming state-of-the-art methods by up to four orders of magnitude in response time. Could this unified approach pave the way for more practical and scalable privacy-preserving location-based services?
The Inevitable Exposure of Spatial Data
Traditional spatial keyword queries, while powerful tools for discovering points of interest, inherently pose significant privacy risks. These queries operate by revealing the precise locations of data objects matching search terms, effectively broadcasting sensitive information about businesses, residences, or even individuals. Consider a search for “coffee shops near me”; the system must expose the geographic coordinates of each relevant establishment, potentially linking those locations to patterns of life or revealing the presence of individuals at specific times. This exposure isn’t limited to commercial data; queries about sensitive facilities – such as healthcare providers or shelters – can inadvertently disclose locations that require protection. Furthermore, even anonymized location data can be re-identified through linkage attacks, combining query results with publicly available information. Consequently, the very mechanism that enables efficient location-based searches creates a pathway for unwanted surveillance and data misuse, necessitating innovative approaches to safeguard spatial data.
Current methods for protecting location privacy in spatial databases frequently introduce significant performance bottlenecks. Techniques like data masking, generalization, and anonymization, while effective at obscuring precise locations, often require extensive data manipulation or the creation of substantial auxiliary data structures. This processing dramatically increases query latency and reduces the system’s ability to handle a large volume of requests – a critical limitation for applications such as real-time traffic monitoring, emergency response systems, or large-scale location-based marketing. Consequently, a trade-off emerges between data security and usability; overly stringent privacy measures can render spatial data queries impractical, effectively negating the value of the information itself. The challenge lies in developing security protocols that minimize this performance impact, enabling efficient and scalable access to sensitive spatial data without compromising individual privacy.
The proliferation of location-based services – from ride-sharing and navigation apps to hyperlocal advertising and emergency response systems – has created an unprecedented demand for spatial data access. This surging need, however, clashes with growing concerns regarding user privacy and data security. Traditional methods of querying spatial data often expose precise location information, creating vulnerabilities to tracking and misuse. Consequently, researchers and developers are actively pursuing innovative approaches that balance the benefits of readily available spatial information with robust security measures and scalable efficiency. These new methods aim to enable meaningful queries without revealing sensitive details, ensuring that the expansion of location-based technologies does not come at the expense of individual privacy and data protection.
RISK: Architecting Security into Spatial Queries
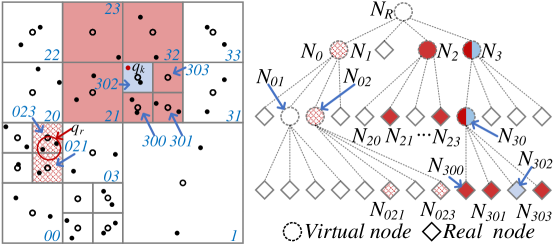
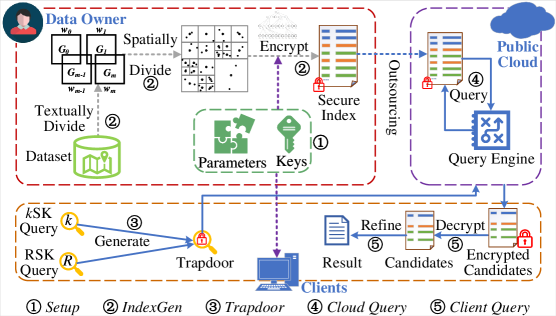
The RISK system utilizes the kQ-tree, a hierarchical spatial indexing structure, to optimize spatial query performance. This index facilitates efficient searching of spatial data by recursively partitioning the data space into smaller regions. Specifically, the kQ-tree supports two primary query types: k-nearest neighbor (kNN) searches, which identify the k closest data points to a given query location, and range spatial keyword queries, which retrieve data points within a specified spatial area and matching keyword criteria. The hierarchical structure of the kQ-tree reduces the search space, enabling faster query execution compared to brute-force approaches, particularly for large datasets. By pre-organizing spatial data, the kQ-tree minimizes the number of data points that must be examined during a query, thus improving overall system responsiveness.
The SkQ-tree, fundamental to the RISK model, achieves data confidentiality through the application of cryptographic techniques during construction. Specifically, each node within the tree incorporates keyed hash functions to generate secure identifiers for spatial regions. These identifiers are then symmetrically encrypted using a session key established between the data owner and the query processor. This process ensures that sensitive location data remains protected at rest and during query operations, preventing unauthorized access even if the underlying tree structure is compromised. The symmetric encryption scheme provides efficient data protection while maintaining query performance, as decryption is performed within the Trusted Execution Environment (TEE).
RISK utilizes a Trusted Execution Environment (TEE) to enhance data security during spatial query operations. The TEE provides an isolated and protected execution environment within the main processor, safeguarding sensitive data and query logic from external software vulnerabilities. Specifically, RISK leverages the TEE to perform cryptographic operations, manage access control policies, and ensure the confidentiality and integrity of spatial data during query processing. This approach minimizes the trusted computing base, reducing the attack surface and mitigating the risk of data breaches or unauthorized access, even if the operating system or other system components are compromised.
RISK incorporates trapdoor generation as a security mechanism to control access to spatial data. A trapdoor is a secret key embedded within a query identifier, allowing only the party possessing the key to successfully retrieve associated data. Specifically, the system generates a unique query identifier linked to the trapdoor; queries lacking the correct trapdoor will fail to decrypt the necessary data blocks within the SkQ-tree. This prevents unauthorized data retrieval by ensuring that even if a query is intercepted, it cannot be used to access sensitive spatial information without the corresponding trapdoor key, thereby safeguarding data confidentiality.
The Cryptographic Underpinnings of Secure Spatial Access
The SkQ-tree employs the Advanced Encryption Standard (AES) algorithm for symmetric encryption of data stored within the index structure. AES, a block cipher, operates on 128-bit blocks with key sizes of 128, 192, or 256 bits, providing a configurable trade-off between security and performance. Utilizing symmetric encryption means the same key is used for both encryption and decryption, necessitating secure key management practices. This approach minimizes computational overhead during query processing compared to asymmetric encryption methods, contributing to the system’s efficiency, while protecting the confidentiality of indexed data at rest.
Keyed hash functions are integral to the RISK system’s security model, providing both data integrity and confidentiality. These functions utilize a secret key during hash computation, linking the hash value directly to the key and preventing unauthorized modification of the indexed data. Any alteration to the data will result in a different hash value, immediately indicating tampering. Furthermore, storing only the hash, and not the plaintext data, protects confidentiality; successful data retrieval requires both the hash and the corresponding secret key, effectively preventing unauthorized access. The specific algorithms used and key management practices are designed to mitigate collision attacks and ensure the robustness of the data protection mechanisms.
The Trusted Execution Environment (TEE) within RISK utilizes the RSA algorithm to facilitate secure key exchange and authentication processes. RSA’s asymmetric encryption capabilities enable the establishment of a secure channel for negotiating and exchanging symmetric keys used for data encryption within the S_kQ-tree. Authentication, performed using RSA digital signatures, verifies the integrity and authenticity of both the querying client and the data owner, ensuring that only authorized entities can access and process sensitive information. This process establishes a trusted environment isolated from the main system, protecting cryptographic keys and query data from external threats and malicious software, and forms the foundation for secure query processing.
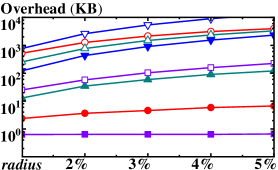
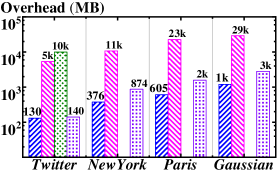
The RISK system’s cryptographic design demonstrably mitigates adaptive chosen keyword attacks, achieving Indistinguishability under Adaptive Chosen Keyword Attacks version 2 (IND-CKA2) security. Benchmarking indicates this approach yields substantial performance improvements over existing solutions, with query response times reduced by up to four orders of magnitude. Furthermore, cloud storage overhead is minimized, exhibiting a reduction ranging from 11 to 33 orders of magnitude when compared to current state-of-the-art methods. These gains are a direct result of the synergistic application of AES symmetric encryption, keyed hash functions, and RSA-based key exchange within a Trusted Execution Environment (TEE).
Scaling Security: Adaptability and Multi-Party Access
The RISK framework distinguishes itself through its inherent capacity to facilitate secure data access across multiple parties simultaneously. This multi-client functionality is achieved not by compromising security protocols, but by intelligently distributing and managing access rights, ensuring each client receives only the data relevant to their authorized queries. Unlike traditional systems requiring bespoke configurations for each additional user, RISK is engineered to scale efficiently, maintaining consistent performance even as the number of concurrent clients increases. Testing demonstrates negligible overhead – response times remain within tens of milliseconds even with up to 100 clients – making it a viable solution for applications demanding collaborative data access without sacrificing speed or security, such as location-based services and distributed databases.
The RISK framework distinguishes itself through a robust data management system capable of handling dynamic information without sacrificing security. Unlike many secure data access methods that struggle with updates, RISK facilitates efficient insertion and deletion of data points, ensuring the system remains current and relevant. This capability is achieved through a carefully designed architecture that segregates data access and modification privileges, employing cryptographic techniques to verify the integrity of all changes. Consequently, the framework avoids the need for costly and time-consuming re-encryption of the entire dataset whenever a single data point is altered, maintaining high performance even with frequently changing information and complex multi-party scenarios.
The RISK framework distinguishes itself through a deliberately modular architecture, streamlining its adoption into pre-existing location-based service (LBS) platforms. This design philosophy prioritizes interoperability, allowing developers to integrate RISK’s secure data access and query capabilities without requiring extensive re-engineering of their current systems. Rather than demanding a complete overhaul, RISK presents itself as a readily available component, facilitating a plug-and-play experience. This approach significantly lowers the barrier to entry, enabling a wider range of applications – from logistics and urban planning to retail and emergency response – to benefit from enhanced privacy and security features without incurring substantial integration costs or delays. The framework’s flexible structure ensures compatibility with diverse LBS environments, fostering innovation and accelerating the deployment of privacy-preserving location services.
Performance evaluations demonstrate the RISK framework’s substantial advantages over the PBKQ system in key operational areas. Specifically, RISK achieves a remarkable reduction in kSK query response time-an improvement of four orders of magnitude-and exhibits a 0.4 order of magnitude enhancement in index construction time. Crucially, this heightened efficiency is maintained even under substantial load; multi-client query response time overhead remains consistently below tens of milliseconds, even when supporting concurrent access from up to 100 clients. These results indicate that RISK not only offers faster data retrieval and indexing but also scales effectively to accommodate numerous users without significant performance degradation, positioning it as a robust solution for demanding, multi-party location-based services.
The presented framework, RISK, acknowledges an inherent truth about all computational systems: even optimized solutions are subject to eventual decay. This mirrors the observation that any improvement ages faster than expected, demanding continuous refinement. The unification of range and k-nearest neighbor queries with a secure hybrid index isn’t merely a technical advancement, but a strategic delay of inevitable entropy. As Donald Knuth aptly stated, “Premature optimization is the root of all evil,” yet RISK demonstrates that thoughtful, secure design isn’t premature, but a proactive measure against the relentless arrow of time and the increasing demands of data privacy in cloud computing.
What Lies Ahead?
The pursuit of secure data processing inevitably reveals the inherent tensions within any system built upon information. This work, demonstrating efficient querying of encrypted geo-textual data, buys time-a valuable, though finite, resource. Systems learn to age gracefully, and the improvements presented here represent a refinement of that process, not an abolition of decay. The unification of range and k-nearest neighbor queries is a pragmatic step, but it does not fundamentally alter the underlying reality: the more functionality a system supports, the more surfaces exist for potential vulnerability.
Future efforts will likely focus on diminishing the performance gap between secure and insecure computations, perhaps through novel encryption schemes or specialized hardware. However, a more interesting, and possibly more fruitful, direction lies in accepting a degree of imperfection. Sometimes observing the process of secure data access-understanding its limitations and trade-offs-is better than trying to speed it up. Perfect security is a phantom; resilient security, capable of adapting to evolving threats, is a more attainable, and perhaps more realistic, goal.
The question isn’t simply how to encrypt data more efficiently, but how to build systems that can withstand inevitable compromise. The focus may need to shift from preventing breaches entirely to minimizing their impact-a move towards damage control rather than absolute prevention. This requires a fundamental re-evaluation of how data is structured, accessed, and ultimately, valued.
Original article: https://arxiv.org/pdf/2602.20952.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Robinhood’s $75M OpenAI Bet: Retail Access or Legal Minefield?
- All Skyblazer Armor Locations in Crimson Desert
- How to Get the Sunset Reed Armor Set and Hollow Visage Sword in Crimson Desert
- How to Catch All Itzaland Bugs in Infinity Nikki
- Speedsters Sandbox Roblox Codes
- Top 10 Must-Watch Isekai Anime on Crunchyroll Revealed!
- Who Can You Romance In GreedFall 2: The Dying World?
- USD CNY PREDICTION
- Invincible: 10 Strongest Viltrumites in Season 4, Ranked
- Madden NFL 26 Cover Star Revealed
2026-02-25 10:20